Статья будет интересна тем, кому мало обычной транслитерации в Excel.
Обратная транслитерация — это одна из самых сложных задач. Казалось бы, просто: «вернуть кириллицу из латиницы». Но на практике всё превращается в настоящий квест. Сотни исключений, десятки языков, тысячи неоднозначностей.
Почему обратный транслит — это сложно
Проблема обратной транслитерации заключается в отсутствии универсальных правил соответствия между латиницей и кириллицей. Одни и те же буквосочетания передаются в русском языке по-разному в зависимости от позиции в слове, фонетического окружения и даже языка-источника.
Например:
- y это обычно «и» (Tiffany → «ТиффанИ»), но может быть и — «ай» (fly → «флай»).
- ch обычно транслитерируется как «ч» (Charles → «Чарльз»), но может быть «х» (charon — харон), «ш» (Chanel — «Шанель») или «к» (Chrysler → «Крайслер»).
- i чаще соответствует «и», но иногда «ай» (Ironman → «Айронмен»).
- man — это и «мен» (супермен, бэтмен) и «ман» (обычно в фамилиях, как Морган Фриман)
- c может читаться как «к» (Canada → «Канада»), «с» (Cinema → «Синема») или даже «ц» (Cerato — «Церато»).
- мягкий знак фактически берется «из ниоткуда» — у него нет эквивалентов в западных языках. Paul — Поль
- Слова французского происхождения — отдельная песня. Renault, Peugeot, Louis, Leroy… Точно не Ренаулт, Пеугеот, Лоуис и Лерои :)
Таким образом, одна и та же комбинация латинских символов не имеет однозначного соответствия в кириллице. Выбор зависит от:
- позиции буквосочетания (начало, середина или конец слова);
- типа слога (открытый или закрытый);
- языка-источника (английский, французский, итальянский и др.);
- устоявшейся традиции написания в русском языке.
Именно поэтому простая подстановка символов «один к одному» даёт результат с множеством ошибок и не соответствует реальному русскоязычному написанию.
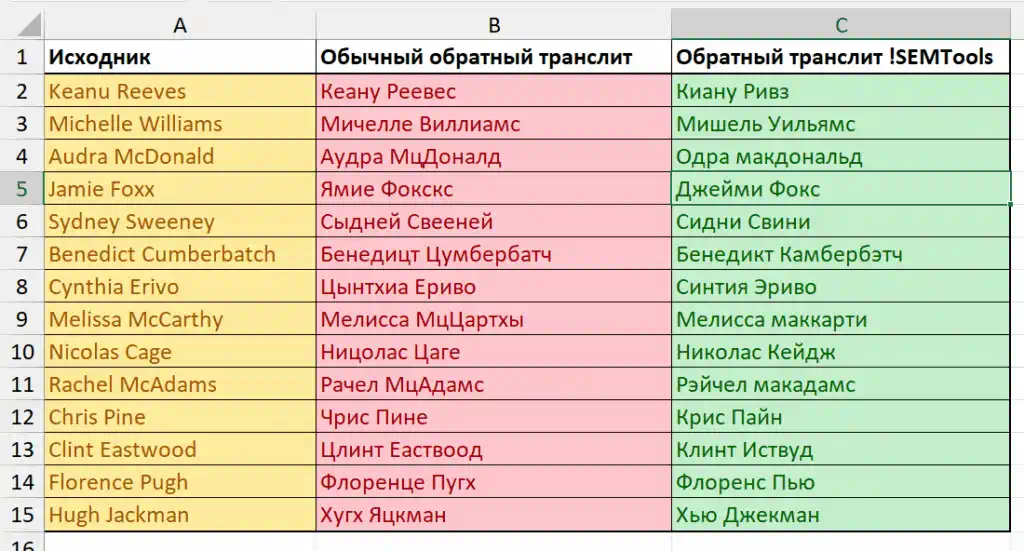
К сожалению, инструмент всё еще не работает с контекстом, и поэтому не всегда даст вам идеальный результат. Например, одному Богу известно, почему Эмма — Уотсон, а доктор — Ватсон. Фамилия у них одна — Watson.
И всё же я сделал то, чего раньше в Excel не было. Я собрал все правила и исключения, проработал самые частотные варианты на основе Wordstat, протестировал на реальных данных: английские имена, автотранспорт, интерьер, бытовая техника, программное обеспечение и т.д..
Результат уже очень хорош — слова восстанавливаются в привычное русскоязычное написание с удивительной точностью. И это подходит не только для этих сфер: алгоритм работает с любой тематикой, где есть термины на латинице.
Теперь это часть !SEMTools. Вы можете за секунды превратить слова на латинице в нормальный читаемый текст, без ручной правки и бесконечных проверок. Никаких аналогов (кроме использования нейросетей, конечно же) у этой процедуры нет.
Кому будет полезен инструмент
- Вебмастерам — для локализации и уникализации контента, работы с метатегами.
- Контент-менеджерам — для массовой транслитерации названий товаров, брендов, географических названий и т.д.
- SEO-специалистам — для кластеризации семантики, составления Title, H1, Description.
- Специалистам по контекстной рекламе — для аналитических задач, для генерации текстовых объявлений, ключевых слов, поиска синонимов.
- Всем остальным, кому нужен обратный транслит :)
Хотите так же?
Быстро решить эту и более 500 других задач в Excel поможет надстройка !SEMTools.