Неявные дубли и их удаление — одна из важнейших задач при работе с текстовым контентом. С подобной задачей часто встречаются SEO и PPC-специалисты, а также вебмастера и контент-менеджеры сайтов.
В семантическом ядре, поисковых запросах и ключевых словах, каталогах товаров, услуг, списках страниц, URL и прочих таблицах со структурированными и не очень текстовыми данными часто встречаются т.н. неявные дубли — ячейки с содержимым, которое по мнению человека повторяет уже имеющееся в таблице, но для компьютера дублем не являющееся из-за минимальных, порой вовсе незаметных различий.
Рассмотрим ситуацию подробнее.
Анализ неявных дублей
Если проанализировать причины, по которым робот видит разницу в содержимом ячеек, можно точно определить несколько таковых. Незначимые для человека, но значимые для компьютера различия — это:
- Изменённый порядок слов в ячейке;
- Лишние пробелы в начале ячейки или между слов
- Не удалённая пунктуация в ячейках;
- Похожие буквы на другом языке;
- Слова и фразы в разных падежах и других видах изменения словоформ;
- В индустрии SEO и PPC — т.н. стоп-слова.
Для каждого типа различий есть и способ устранить их:
- Сортировка слов внутри ячейки решает проблему с разным порядком слов;
- Удаление всех символов, кроме букв и цифр (и пробелов) устранит и возможные различия в них;
- Для исправления различий словоформ используется лемматизация.
После устранения всех различий можно выявить дубликаты внутри столбца и проанализировать, какие фразы неявно дублируют друг друга. Получится три столбца — исходные фразы, нормализованные фразы и статусы их дублирования.
Удалить неявные дубли в 1 клик
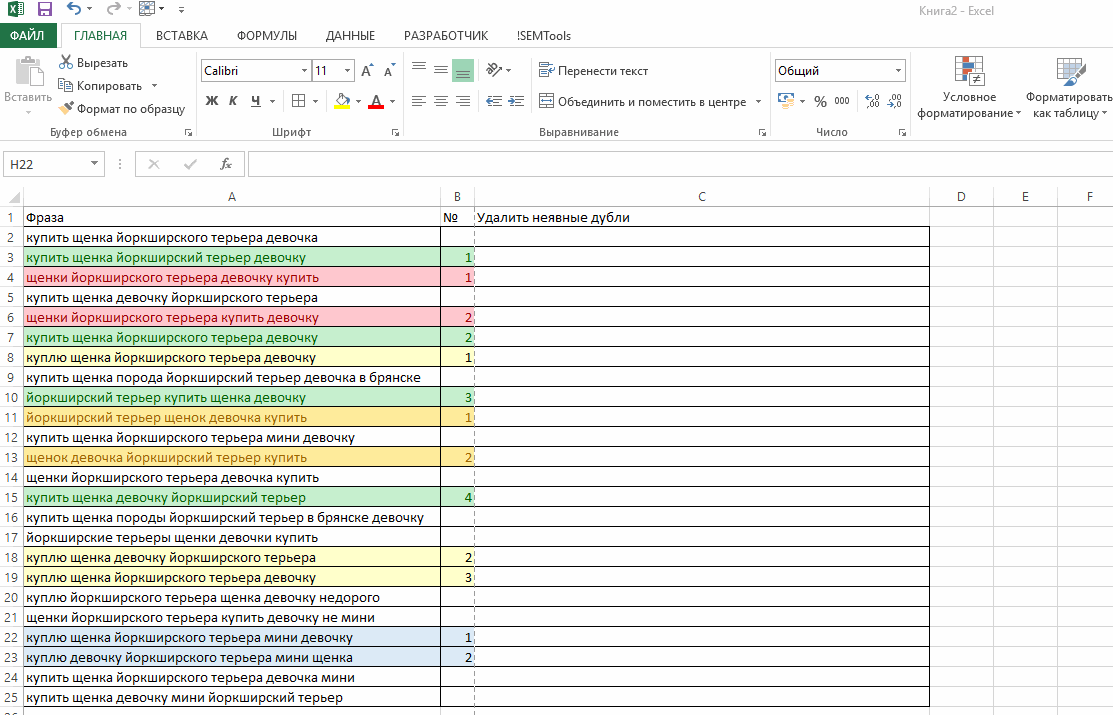
Как удалить дубликаты фраз, в которых слова различаются лишь их порядком? Подобный инструмент доступен в меню !SEMTools «УДАЛИТЬ» — «Ячейки» — «Дубли внутри диапазона». Ниже наглядная демонстрация работы. Макрос работает аналогично обычному удалению дубликатов без смещения — просто очищает содержимое ячейки, если в ней обнаружен неявный дубль одной из ячеек выше.
Удаление неявных дублей с учётом словоформ
В контекстной рекламе и SEO при проработке семантического ядра бывает важно избавиться в том числе от дублей, в которых различия не только в порядке слов, но и в словоформах. В примере выше видно, что дубликаты такого типа там не удаляются.
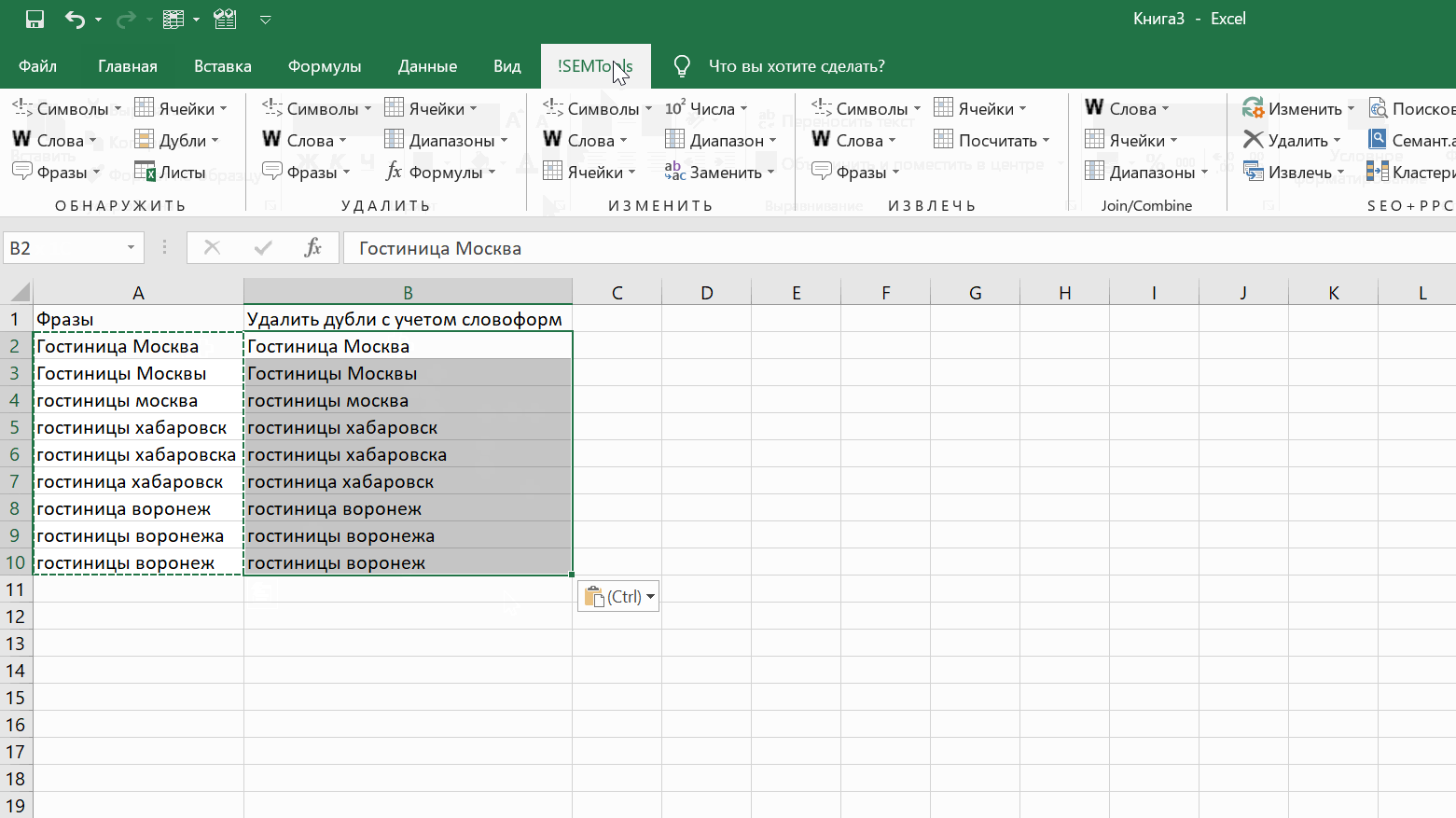
Для решения проблемы может помочь такой процесс, как лемматизация. Чтобы не пришлось создавать дополнительный столбец, над которым производить процесс лемматизации, в меню удаления дублей также был добавлен пункт удаления дубликатов слов и фраз вместе с ней. При этом исходные фразы не меняются — лемматизация происходит в фоновом режиме и используется только для сравнения фраз.
Удаление неявных дублей другого столбца
Когда нужно просто сравнить два диапазона между собой и удалить дубли из первого, задача не кажется сложной. Это можно сделать даже с помощью условного форматирования или функции ВПР. Но вот если во втором столбце содержатся неявные дубли, и их тоже хочется удалить, без навыков программирования вам точно не обойтись. Однако, есть и простое решение — соответствующая процедура надстройки !SEMTools.
В пару кликов вы можете сравнить диапазоны между собой и удалить неявные дубли, не прибегая к помощи программистов или поиска готовых решений на форумах по Excel. Демонстрация работы инструмента ниже:

Как мы видим, неявно дублирующиеся ячейки в первом диапазоне были успешно найдены во втором, и были удалены.
Процедура доступна как в Pro, так и Lite версии надстройки !SEMTools.