Иногда поиск слов в ячейках не отвечает на все вопросы, так как одно слово само по себе не всегда несет однозначный смысл.
Например, слова «минеральные» и «воды» по отдельности могут встречаться в контексте, не связанном с названием города: «минеральные источники», «минеральные соли», «минеральные плиты», «купи воды», «отключение воды», «температура воды», «счетчик воды» и т.д.
Однако, когда два этих слова идут строго друг за другом:
«минеральные воды»,
«минеральных водах»,
«минеральных вод»,
«минеральных водах»,
«минеральным водам»
— мы знаем, что речь о городе Минеральные Воды.
То же касается и множества других видов омонимии.
Например, «то» может быть местоимением, союзом, частицей и существительным-аббревиатурой «техническое обслуживание».
В таких случаях только соседние слова могут дать понимание, какой смысл несет слово в контексте:
нулевое ТО
то как зверь она завоет, то заплачет…
я за то люблю Ивана…
Ровно для таких характерных случаев и были предусмотрены макросы !SEMTools по поиску, извлечению и удалению фраз в ячейках. Ниже примеры использования поиска по встроенному списку топонимов и произвольно задаваемому списку фраз.
Как найти в тексте топонимы
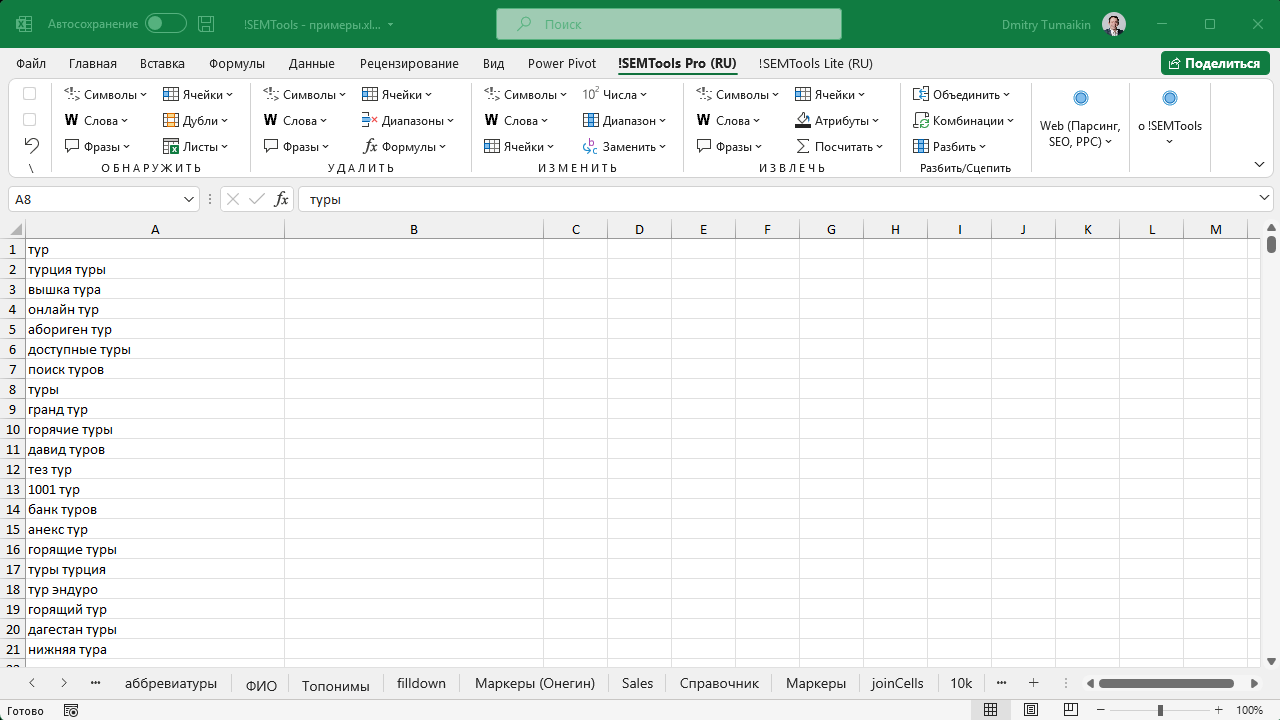
На первом этапе обработки семантического ядра может быть полезно обнаружить города в ячейках — в каких ячейках есть их названия, а в каких их нет. Уже после этого можно будет принимать дальнейшие шаги — извлечь города или удалить города из ячеек.
Процедура поиска крайне скоростная. Вот так за несколько секунд можно разметить на предмет наличия в них городов и стран миллион фраз:
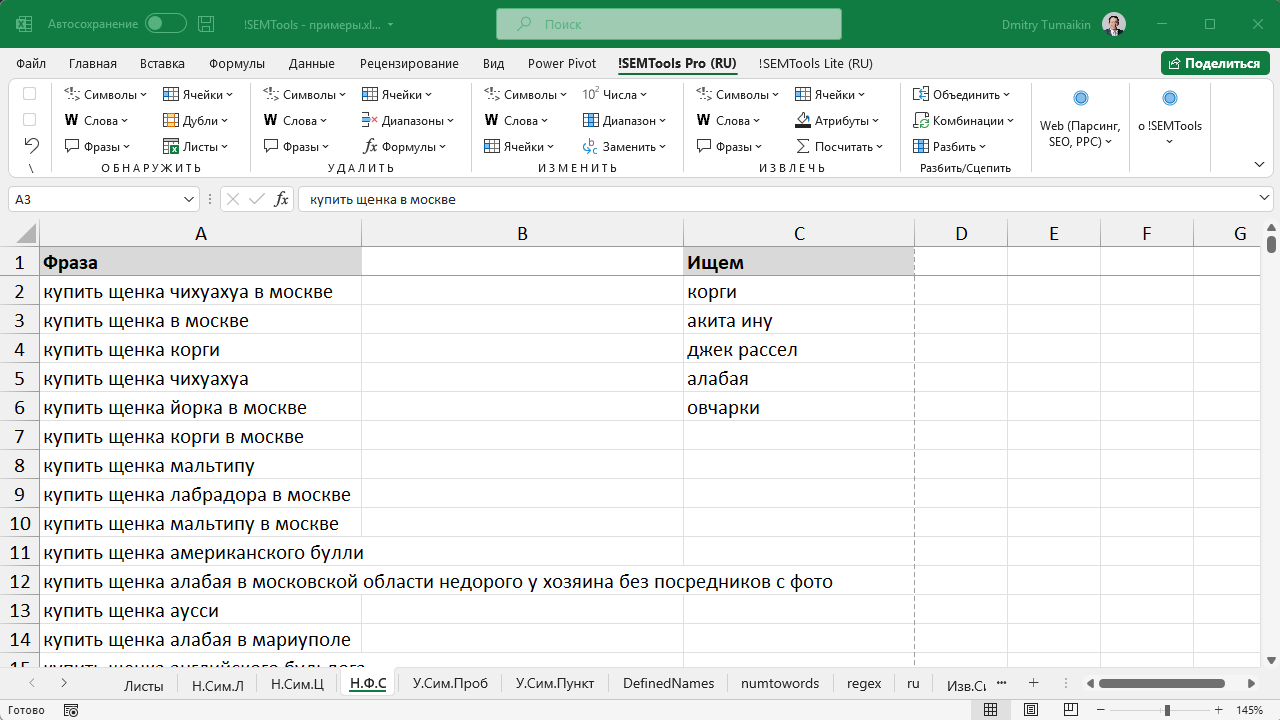
Как найти в тексте свой список фраз
При выполнении данный макрос может искать как фразы, так и слова, поэтому нет проблемы использовать смешанные списки из слов и фраз.
Хотите так же? ;)
Похожие инструменты:
Извлечь слова из текста в Excel
Добрый день. Спасибо за замечательный инструмент.
Проблема в следующем: инструмент не всегда находит/удаляет все топонимы (например, не обнаруживает станции метро Москвы).
Можно ли как-то самостоятельно пополнять список топонимов, к которому обращается инструмент?
Самостоятельно, к сожалению, не получится. Но для самостоятельного поиска и удаления можно всегда использовать процедуры поиска, удаления и замены фраз. Составляете свой собственный список и используете его. Если будет требоваться часто — сохраните где-нибудь в удобном месте на компьютере :)
Проблема с метро Москвы в том, что они часто омонимичны именам собственным. Беговая, университет, тульская, речной вокзал, сокол и т.д. Раньше были в списке топонимов, но потом удалил.