С этим докладом я выступил на SEMConf 2018. Ниже транскрипт записи моего доклада.
Обновленный файл презентации: Стоп-слова — друзья или враги.
«Стоп-слова — служебные части речи и местоимения, а также любые слова, не несущие дополнительного смысла, которые автоматически исключаются из запроса пользователя при отборе объявлений для показа».
Справка Яндекс.Директа
Главное отличие стоп-слов в том, что они детерминированы, а минус-словом может быть любое слово.
Основное в определении стоп-слов — то, что это слова, не несущие смысла. Однако это понятие относительное. Есть «неоднозначные» стоп-слова, например, «то» (техобслуживание), «тех» (тех характеристики = технические характеристики), «тем» (много интересных тем). И зачастую стоп-слова кардинально меняют смысл фраз. Именно это и есть главная мысль этого материала.
Точный список стоп-слов Яндекс.Директа неизвестен и иногда меняется.
Как определить стоп-слова?
Я знаю четыре способа:
- Через заведение группы в интерфейсе: слова без стоп-слова и со стоп-словом «схлопываются», остается только слово без стоп-слова.
- Через кросс-минусовку и удаление дублей в Коммандере.
- Через Прогноз бюджета в интерфейсе: если при запросе частотности система ругается «Ключевая фраза не может состоять только из стоп-слов: союзов, предлогов, частиц». Причем, в отличие от Вордстата, не дает это сделать даже с применением операторов.
- Через Wordstat Яндекса: если отдает 0 показов по слову:
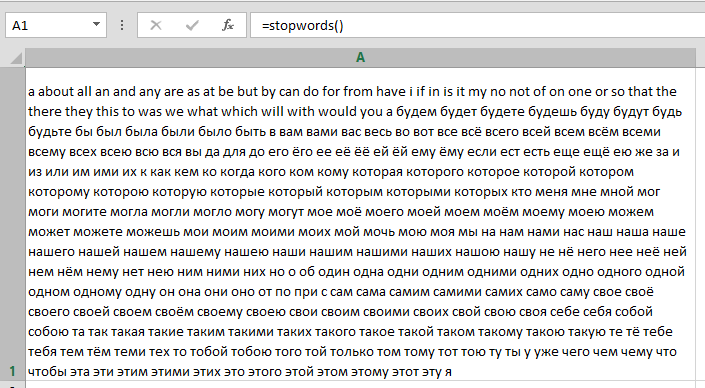
Удивительное в том, что эти варианты отдают разные данные, есть небольшой рассинхрон. Я взял за истину прогноз бюджета. На текущий момент мной найдены 295 имеющих смысл слов.
Все их можно вывести в ячейку в Excel, вбив функцию stopwords. У функции нет аргументов, ее задача просто вывести все стоп-слова. Работать будет только если у вас установлена надстройка.
Для Google Ads список стоп-слов может быть шире: каких-то ограничений на это в Ads нет необходимости устанавливать. Фактически Ads может посчитать стоп-словом любое слово, перед которым вы не поставите модификатор широкого соответствия — выбор стоп-слов за вами.
Использование операторов соответствия при работе со стоп-словами
Работа со стоп-словами подразумевает проставление либо удаление модификаторов перед ними.
Удалять модификаторы может быть нужно в нескольких случаях:
- Запрос в Директе состоит из семи слов без стоп-слов, с модификаторами — система не пропустит.
- Есть риск потерять охват из-за того, что пользователи могут не употреблять стоп-слова в запросе, а эквивалентных фраз без стоп-слов нет.
- Стоп-слова добавлены умышленно, для приукрашивания шаблонных заголовков.
Проставлять модификаторы нужно во всех обратных случаях.
Поскольку подход к стоп-словам в Директе и Ads различный, я сделал в своей надстройке два списка стоп-слов: общий и только для Директа. Каждый из списков можно использовать в макросах: удалить стоп слова, удалить операторы перед ними, проставить операторы «!» или «+». Выбор операторов обусловлен тем, что некоторые стоп-слова склоняются, например, весь, все, всех, всем и т. д.
Стоп-слова как маркер интента
Стоп-слова можно классифицировать по интенту. Этот лайфхак я обнаружил довольно давно и пользовался им при проработке минус-слов. Он заключается в том, что стоп-слова в сочетании с продвигаемой сущностью (услуга или товар) могут характеризовать запрос пользователя как релевантный или нерелевантный. На пути пользователя (customer journey map) основополагающий параметр, влияющий на взаимодействие с продуктом/услугой — временной промежуток. Утрируя, это до и после. Также пользователь может сомневаться и искать альтернативы — это происходит во время основного поиска.
Исходя из этого, я промаркировал стоп-слова по интенту, чтобы на их основе вычислять нерелевантные запросы.
До приобретения услуги / покупки товара
Сюда входит много запросов, связанных с людскими страхами, сомнениями и стремлением их развеять путем обращения к поиску. Это — «теплая» аудитория, как правило, она не отличается высокой конверсией, но при умелой работе может приносить прибыль, так как зачастую с ней предпочитают не возиться и оставляют на потом ваши конкуренты.
Слова-маркеры:
- перед
- какой/какая/какие… + сущность
- вред
- последствия
- если
- о/об + услуга/товар
- при + услуга в сфере услуг
- ли (больно ли, вредно ли, стоит ли, нужно ли, можно ли, возможно ли, хорошо ли, правда ли…)
- и, разумеется, до + услуга — в сфере услуг
После приобретения услуги / покупки товара
Сюда относятся поисковые запросы, обозначающие возникающие у пользователя проблемы уже после покупки товара или услуги. Это могут быть какие-либо дефекты товара или последствия некачественно оказанной услуги, необходимость замены, возврата, ремонта товара или поиск консультационного материала (что делать и как действовать в новых реалиях).
Основные маркеры:
- для + сущность
- под/подо + сущность
- на + сущность (кроме маркеров покупки: цена на товар, скидки на товар)
- в/во + сущность
- к/ко + сущность
- от + сущность
- сущность + не
- сущность + глагол (кроме глаголов-маркеров покупки)
- как (в товарной семантике, кроме фраз с маркерами покупки)
- после + сущность — в сфере услуг
Вместо услуги/товара
Здесь все просто: пользователь или вовсе не наш потенциальный клиент, или вероятность этого около 100%. Он ищет альтернативу нашему продукту, причем необязательно платную. Видов подобных интересов и деятельности много, портреты пользователя могут быть совершенно разные:
- Студент или специалист. Ищет статьи, рефераты, курсовые, курсы, образовательные заведения и т. д.
- DIY-энтузиаст. Ищет руководства и инструкции, пытается все сделать своими руками.
- Любитель порно.
- Искатель смысла. Интересуется сонниками, гороскопами, приметами, молитвами, гаданиями, приворотами и т. д.
- Геймер.
- Заядлый онлайнер. Его поведение перекликается с некоторыми вышеупомянутыми. Ищет анекдоты, приколы, видяхи, дровишки, софт, обои для рабочего стола и прочие похожие сущности. Эти слова не относятся к стоп-словам, но без их использования проработка нецелевой семантики была бы менее эффективной.
Из стоп-слов, характерных для подобного портрета:
- без + сущность
- вместо + сущность
- зачем + сущность или сущность + зачем
- почему + сущность или сущность + почему
- или + сущность или сущность + ли
- ли + сущность или сущность + ли
И этот список далеко не полный и будет существенно пополняться.
Минус-слова через стоп-слова — подробный алгоритм подбора
Зная интент, который дают фразам стоп-слова, и понимая релевантность самого интента, мы можем автоматизировать сбор нерелевантных слов. Получится такая в своем роде кластеризация фраз по интенту через стоп-слова.
Алгоритм:
- Выбираем нерелевантный интент.
- Выбираем стоп-слова, характеризующие его.
- Анализируем порядок следования стоп-слов и продвигаемой сущности.
- Выбираем из семантического ядра все фразы с зафиксированными последовательностями
- Удаляем очевидно полезные слова: маркеры покупки, эпитеты, геомаркеры, стоп-слова.
- Profit! Но лучше пройтись по списку глазками, прежде чем добавлять в минус-слова на уровне РК.
Как воспользоваться макросом
Найти макрос можно на панели моей надстройки в разделе SEM & SEO, в меню «семантический анализ». Нужно выделить диапазон, содержащий в себе поисковые запросы, и нажать «поиск нерелевантных слов«.
Неочевидные сложности и их решение
- Иногда между стоп-словом и продвигаемой сущностью может быть другое слово (например, эпитет). Это снизит количество найденных минус-слов, и лучше удалять прилагательные перед запуском скрипта.
- Услуга может использоваться в запросе в любом склонении, поэтому нужна либо морфология, либо использование услуги во всех склонениях. Немного пожертвовав юзабилити и упростив разработку, я выбрал второй вариант. Однако в скором времени будет достаточно ввести одно слово, т.к. склонение по падежам в !SEMTools уже доступно.