Статья описывает бесплатные формулы, а также процедуры !SEMTools версии Lite и Pro.

Как найти повторы слов в ячейке Excel?
Долгое время поиск повторяющихся слов внутри одной ячейки в Excel был сложной задачей, требующей сложных комбинаций функций или написания VBA-макросов. Пользователям приходилось прибегать к обходным путям: разбивать текст на отдельные столбцы, писать громоздкие формулы или использовать VBA.
Ситуация кардинально изменилась с появлением в Excel 365 новых динамических функций. Теперь для обнаружения повторов слов в ячейке можно использовать элегантные формулы, работающие с массивами. Ключевыми стали функции ТЕКСТРАЗД и УНИК, которые позволяют легко разбивать текст на слова и анализировать их на уникальность.
Найти повторы слов в ячейках — формула Excel 365
Вот пример формулы, которая возвращает ИСТИНА, если в ячейке A1 есть повторяющиеся слова, и ЛОЖЬ, если все слова уникальны:
=СЧЁТЗ(ТЕКСТРАЗД(A1;" ")) > СЧЁТЗ(УНИК(ТЕКСТРАЗД(A1;" ");ИСТИНА))
Разберем формулу по шагам:
- ТЕКСТРАЗД(A1;» «) — разбивает текст в ячейке A1 на отдельные слова используя пробел как разделитель
- УНИК(ТЕКСТРАЗД(A1;» «);ИСТИНА) — возвращает только уникальные слова из полученного массива
- СЧЁТЗ(ТЕКСТРАЗД(A1;» «)) — подсчитывает общее количество слов
- СЧЁТЗ(УНИК(ТЕКСТРАЗД(A1;» «);ИСТИНА)) — подсчитывает количество уникальных слов
- Сравнение через > показывает, есть ли разница между общим и уникальным количеством слов
Если присмотреться внимательно — формула находит далеко не все повторы, например, в четвёртой строке ей мешает пунктуация, а в пятой и седьмой — разные словоформы слов.
Поэтому для более качественного поиска могут потребоваться дополнительные действия. Смотрите статьи на тему:
Как удалить знаки препинания в Excel
Найти и удалить повторы слов в ячейках в 2 клика
Несмотря на появление этих возможностей в Excel 365, многие пользователи продолжают сталкиваться с ограничениями: формулы становятся громоздкими при работе с большими объемами данных, требуют глубокого понимания работы с массивами и не всегда интуитивно понятны. Именно поэтому инструменты надстройки !SEMTools для поиска и удаления повторяющихся слов остаются востребованными — они предлагают простой визуальный интерфейс и мгновенную обработку данных без необходимости написания сложных формул.
Данная процедура имеет исключительно простой алгоритм, который ищет внутри ячеек повторяющиеся слова. Если в ячейке есть слова, которые повторяются, она возвращает ИСТИНА, если повторяющихся слов нет — возвращает ЛОЖЬ. При этом повторяющимися словами являются исключительно полные совпадения слов.
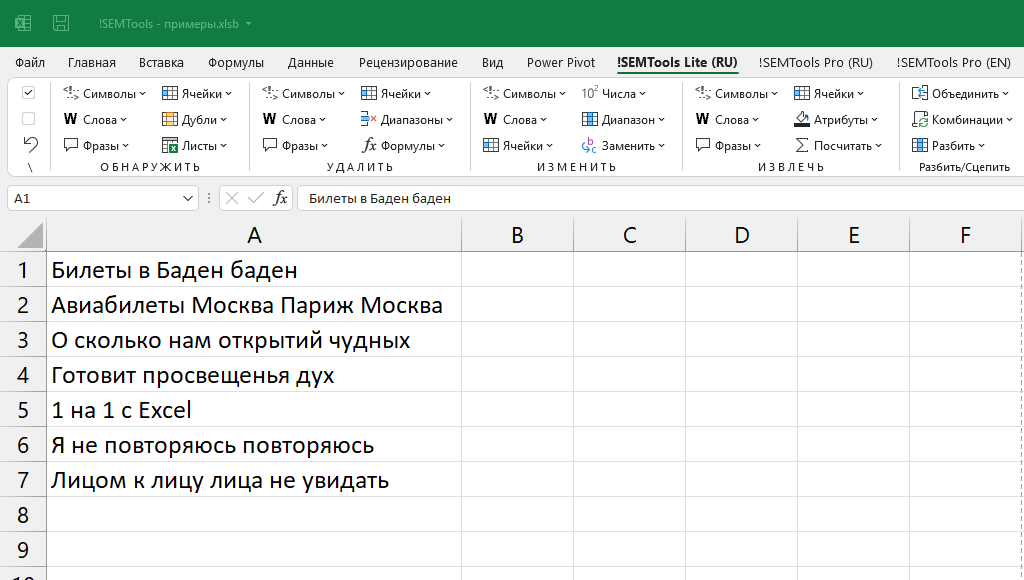
Что является словом? В понимании макроса им считается:
- Набор символов, отделённых пробелами друг от друга в середине строки;
- Набор символов в конце строки, отделённых пробелом слева;
- Набор символов в начале строки, отделённых пробелом справа.
Поиск ячеек с повторяющимися словами рекомендуется производить перед удалением повторов слов, дабы визуально удостовериться, в каких фразах слова встречаются неоднократно.
В обработке семантического ядра часто данную операцию имеет смысл производить вместе с лемматизацией, чтобы удалить повторы разных словоформ одного и того же слова.
Запуск производится через меню «Слова -> Повторяющиеся слова» в группе «ОБНАРУЖИТЬ».
Найти наиболее повторяющиеся слова в тексте
Если задача стоит не просто найти повторы, но обнаружить наиболее повторяющиеся слова в целом столбце текста, в таком случае потребуется провести частотный анализ n-грамм, что также доступно в Excel с !SEMTools. Поскольку наиболее востребована операция поиска n-грамм бывает у SEO и PPC-специалистов, она находится в соответствующей группе: инструменты для SEO и контекстной рекламы.
Ниже пример, иллюстрирующий поиск наиболее популярных слов в семантике этой статьи. Находим наиболее повторяющиеся слова в диапазоне и выводим их списком с количеством повторений. Предварительно рекомендуется удалить пунктуацию и сделать все буквы строчными.
Читайте подробнее: Частотный анализ N-gram в Excel
Смотрите также:
Удалить повторы слов в ячейках Excel
Не нужно быть программистом, чтобы найти повторы слов в ячейках! С !SEMTools вы можете мгновенно находить и удалять повторяющиеся слова в тексте — без сложных формул и макросов, прямо в Excel!