Многие слышали, что такое регулярные выражения, но не всем известно, что они поддерживаются «под капотом» Microsoft Excel. Регулярные выражения дают возможность многократно ускорить работу с текстом, находить в нем самые замысловатые паттерны и решать самые сложные исследовательские задачи.
На текущий момент нативные функции регулярных выражений есть только в Excel 365, в более старых версиях их нет. Поэтому для их использования в более старых версиях Excel необходимо использовать VBA.
Но с надстройкой !SEMTools это не нужно!
Зато минимальное понимание синтаксиса регулярок позволит с легкостью решать задачи, решение которых практически невозможно с помощью стандартных функций, либо для этого требуются формулы огромной длины. Примеры таких мегаформул можно посмотреть в решении задач:
Функции регулярных выражений в Excel
Для поддержки регулярных выражений при наличии подключенной надстройки !SEMTools в Excel будут работать три функции: REGEXMATCH, REGEXEXTRACT и REGEXREPLACE.
Их синтаксис и принцип работы аналогичен синтаксису Google Spreadsheets. Поэтому формулы, составленные в Excel, будут иметь полную зеркальную совместимость с Google Spreadsheets.
REGEXMATCH
REGEXMATCH возвращает ИСТИНА или ЛОЖЬ (TRUE или FALSE в английской версии Excel), в зависимости от того, соответствует текст паттерну или нет.
=REGEXMATCH("текст";"RegEx-паттерн для поиска")
REGEXEXTRACT
REGEXEXTRACT извлекает первый попадающий под паттерн фрагмент текста. Небольшое отличие от Google Spreadsheets заключается в том, что, если в искомом тексте такого фрагмента нет, Spreadsheets отдают ошибку, а в надстройке отдается пустая строка.
=REGEXEXTRACT("текст";"RegEx-паттерн для поиска")
REGEXREPLACE
REGEXREPLACE заменяет все попадающие под паттерн фрагменты на указанное значение.
=REGEXREPLACE("текст";"RegEx-паттерн для поиска";"текст, которым заменяем найденное")
Примеры задач, решаемых с помощью регулярных выражений
Я не поскуплюсь на примеры, чтобы показать вам все возможности регулярных выражений, так как они действительно огромны. Надеюсь, эта статья послужит руководством и стимулом активнее пользоваться их мощью. От простого к сложному.
Чтобы дать обычным пользователям Excel возможность максимально широко использовать возможности регулярных выражений, в надстройку !SEMTools был добавлен ряд быстрых процедур. Все примеры ниже будут показаны с их использованием.
Извлечение данных из ячеек с помощью RegEx
Извлечь из ячейки содержимое до / после первой цифры включительно
.+\d
\d.+
Такие простые два выражения. «+» — это служебный символ-квантификатор. Он обеспечивает «жадный» режим, при котором берутся все удовлетворяющие выражению символы до тех пор, пока на пути не встретится не удовлетворяющий ему или наступит конец/начало строки. Точка обозначает любой символ. Таким образом, берутся любые символы до конца строки, перед которыми есть цифра.
«d» обозначает «digits», иначе цифры. Поскольку квантификатора после «\d» в примерах выше нет, то одну цифру. Если потребуется исключить из результатов эту цифру, это можно сделать позднее. В !SEMTools есть простые способы удалить символы в начале или конце ячейки.
Цифры можно выразить и другим регулярным выражением:
[0-9]
«Вытянуть» цифры из ячеек
Как извлечь из строки цифры? Регулярное выражение для такой операции будет безумно простым:
\d
В зависимости от режима извлечения результатом будет либо первая, либо все цифры в ячейке.
Если их нужно вывести не сплошной последовательностью, а через разделитель, сохранив фрагменты, где символы следуют друг за другом, выражение будет чуть иным, с «жадным» квантификатором. А при извлечении нужно будет использовать разделитель.
\d+
[0-9]+
Это справедливо и для любых других символов, пример с числами ниже:
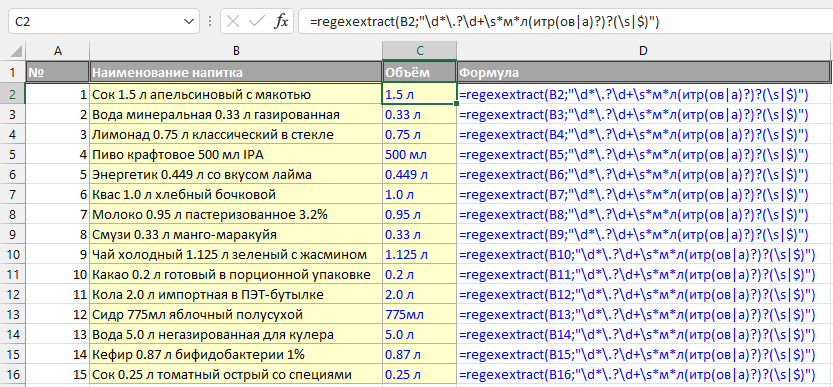
Извлечь из ячейки числа из N цифр
Как видно в примере выше, помимо чисел, обозначающих годы, были извлечены и другие числа, например, «1». Чтобы извлечь исключительно последовательности из четырех цифр, потребуется видоизменить выражение. Есть несколько вариантов:
\d\d\d\d
[0-9][0-9][0-9][0-9]
\d{4}
[0-9]{4}
Последние два варианта включают квантификатор фигурные скобки. Он указывает минимальное количество повторений удовлетворяющего паттерну символа или фрагмента строки. Паттерну, стоящему непосредственно перед квантификатором. В данном случае подряд должны идти любые четыре символа, являющиеся цифрами.
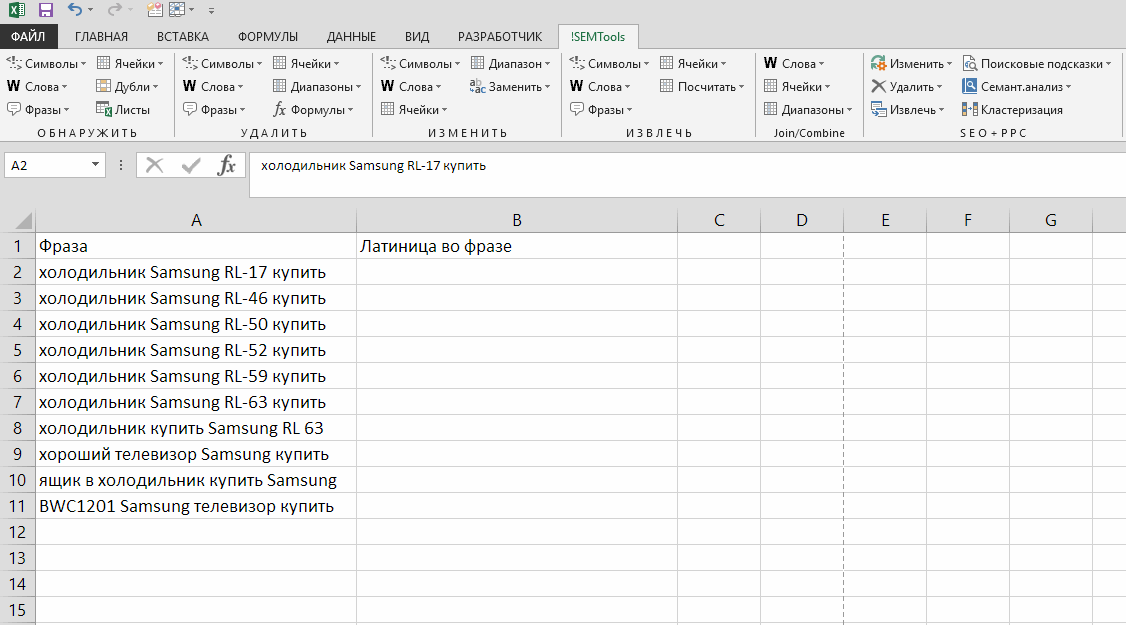
Извлечь латиницу регулярным выражением
Выражение [a-zA-Z] обозначает все символы латиницы. Дефис и в этом, и в предыдущем случае обозначает, что берутся все символы между a и z и между A и Z в общей таблице символов Unicode. Квадратные скобки — синоним «ИЛИ». Рассматривается каждый из элементов или множеств внутри квадратных скобок, при этом выражение не находит ничего, только если сравниваемая строка не содержит ни одного элемента внутри квадратных скобок.
Извлечь символы в конце/начале строк по условию
Стандартные формулы ПРАВСИМВ и ЛЕВСИМВ позволяют извлечь из ячейки соответственно последние и первые N символов, но на этом их возможности заканчиваются.
С помощью же регулярных выражений можно извлечь:
- Символы, идущие после и включая последнюю заглавную букву в ячейке, заканчивающейся на восклицательный знак. Так мы извлечем из ячеек все восклицательные предложения. Выражение для этого выглядит так: [А-Я][а-яa-z0-9 ]+!$.
- Первые N выбранных символов из определенного множества, если ячейка с них начинается.
- Аналогично: последние N определенных символов, если ячейка на них заканчивается.
Проверить ячейки на соответствие регулярному выражению
Если нет необходимости извлекать данные, а нужно лишь проверить, соответствуют ли они паттерну, чтобы потом отфильтровать их, удобнее использовать процедуру, эквивалентную формуле REGEXMATCH.
Найти в ячейке числа из N цифр
В зависимости от того, является N необходимым или достаточным условием, нужны разные регулярные выражения. Иными словами, считать ли последовательности из N+1, N+2 и т.д. цифр подходящими или нет. Если да, выражение будет таким же, как уже указывалось выше:
\d\d\d\d
[0-9][0-9][0-9][0-9]
\d{4}
[0-9]{4}
Если же нас интересуют строго последовательности из N цифр, задачу придется производить в две итерации:
- В первую итерацию извлекать цифры вместе с границами строк или нецифровыми символами, идущими после/перед (это станет своеобразной проверкой отсутствия других цифр).
- И во вторую уже сами цифры.
Выражения для первой итерации будут, соответственно:
(^|\D)\d\d\d\d($|\D)
(^|\D)[0-9][0-9][0-9][0-9]($|\D)
(^|\D)\d{4}($|\D)
(^|\D)[0-9]{4}($|\D)
Если внимательно посмотреть на отличие в синтаксисе, можно понять, что означают символы в нем:
- вертикальная черта «|» обозначает «ИЛИ»,
- скобки «( )» нужны для перечисления внутри них аргументов и «отгораживания» их от остального выражения,
- каретка «^» обозначает начало строки,
- символ доллара «$» — конец строки,
- \D — нечисловые символы. Обратите внимание: верхний регистр меняет значение \d на противоположное. Это справедливо также для пар \w и \W, обозначающих латиницу и цифры и не-латиницу и цифры, и \s и \S, различные виды пробелов и не-пробельные символы соответственно.
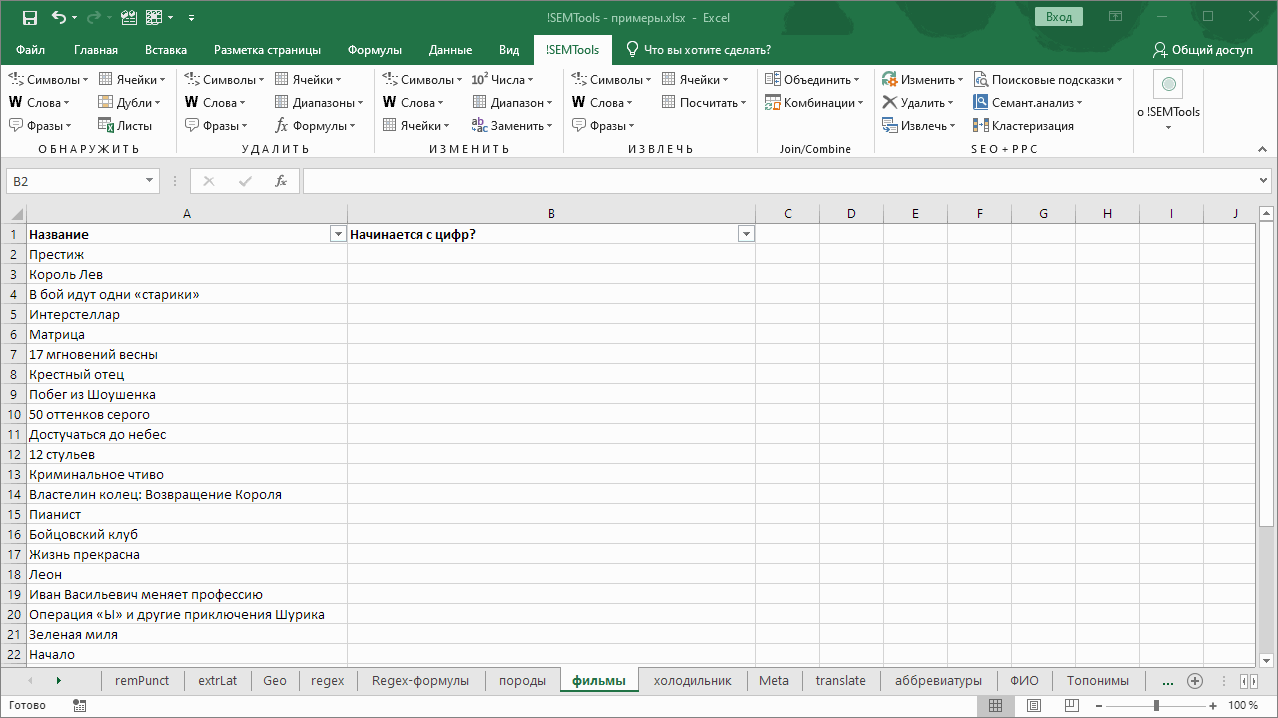
Найти ячейки, начинающиеся с цифр
Выражение для подобной проверки будет:
=REGEXMATCH(A1;"^\d.*")
Либо можно воспользоваться процедурой проверки на копии исходного диапазона без необходимости вводить формулу. Смотрите примеры.
Замена подстрок по регулярному выражению
Наиболее частый кейс такой замены — замена на пустоту, когда наша задача попросту удалить из текста определенные символы. Наиболее популярны:
- удаление цифр из текста,
- удаление пунктуации,
- всех символов, кроме букв и цифр.
Но бывают случаи, когда необходима реальная замена, например, когда нужно заменить буквы с «хвостиками»/умляутами/ударениями и прочими символами из европейских алфавитов на их английские аналоги. Задача популярна среди SEO-специалистов, формирующих урлы сайтов этих стран на основе оригинальной семантики. Так выглядит начало таблицы паттернов для замены диакритических символов на латиницу с помощью RegEx при генерации URL:

Разбить ячейку по буквам
Чтобы разбить ячейку посимвольно, достаточно извлечь все символы через разделитель. Выражением для извлечения будет обычная точка — она как раз и обозначает любой символ.
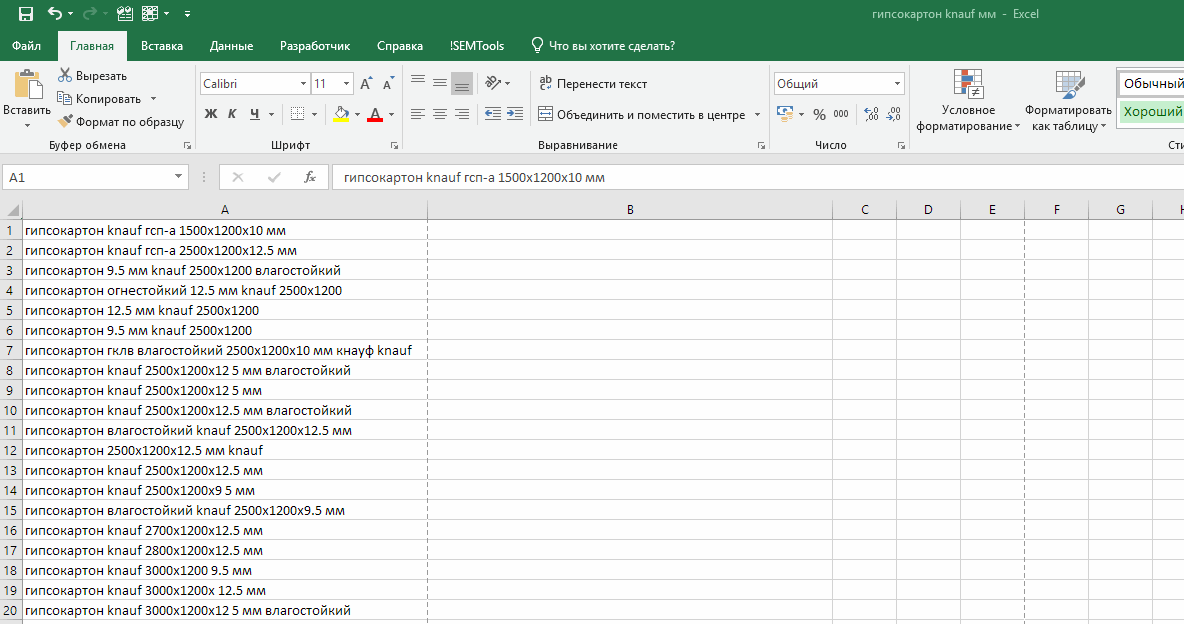
Разбить буквы и цифры в ячейке
Если строго соблюдать постановку этой задачи, ее выполнить довольно сложно. Но зато с помощью регулярных выражений можно отделить цифровые последовательности символов от нецифровых. Так будет выглядеть выражение:
([^\d.]+|[\d.]+)
А так будет выглядеть процесс на практике:
Вставить текст после первого слова
При замене по регулярному выражению в !SEMTools есть опция замены не всех, а только первого найденного фрагмента, удовлетворяющего паттерну. Это позволяет решить задачу вставки символов после первого слова. Просто заменим первый пробел на нужные нам символы с помощью соответствующей процедуры (эту задачу можно решить также с помощью функции ЗАМЕНИТЬ, но можно и воспользоваться функционалом замены по регулярному выражению). В отличие от штатной процедуры «Найти и заменить«, здесь можно заменить только первое вхождение. В данном случае — первый пробел. Как видно, пробел ничем не отличается от обычного:
Вставить символ после каждого слова или перед ним
Надстройка решает эту задачу в два клика готовой процедурой в меню «Изменить слова«, но можно воспользоваться и несложным выражением для замены:
($| )
(^| )
Выражения обозначают, что заменяются пробелы или конец строки в первом случае и пробелы или начало строк во втором. Вертикальная черта — то самое «ИЛИ».
А заменять будем, соответственно, на пробел с символом слева или справа. Процедура добавит лишний пробел перед ячейкой или после, поэтому от него желательно будет избавиться — удалить лишние пробелы или удалить символы в начале / конце ячейки.
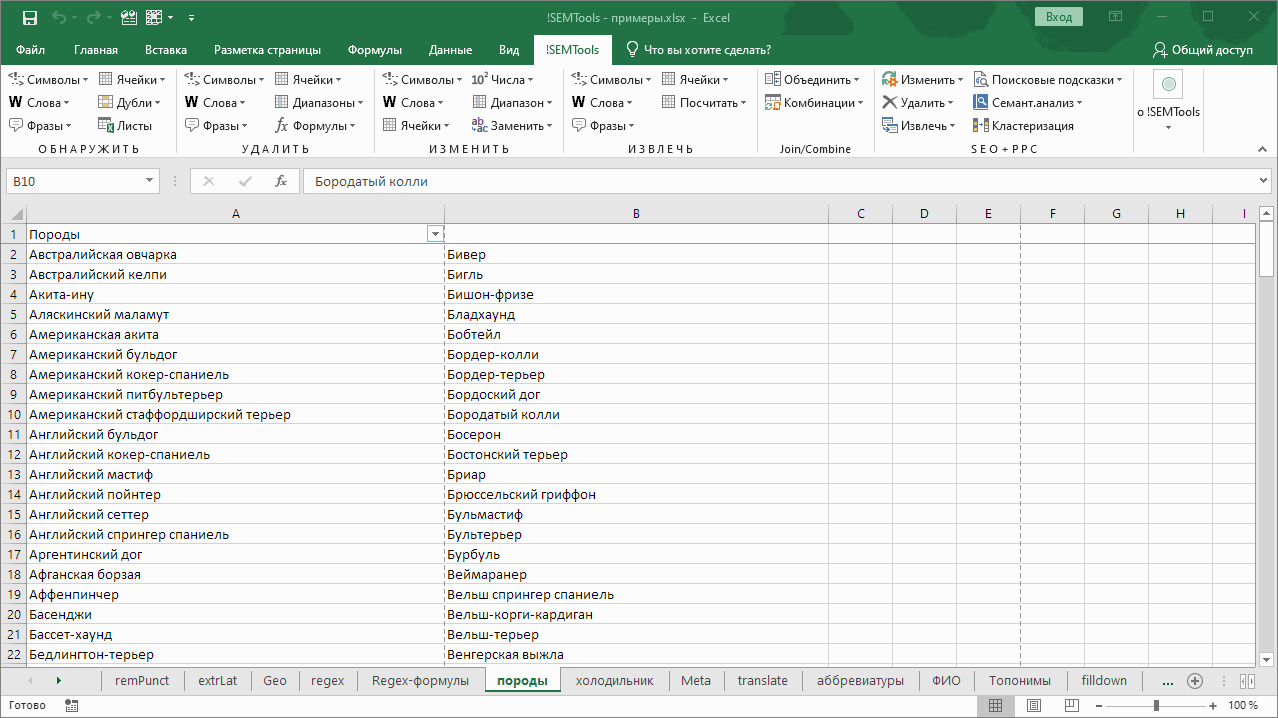
Регулярные выражения для поиска конкретных слов в !SEMTools
Когда дело доходит до извлечения определенных слов, регулярные выражения становятся невероятно сложными. Поэтому надстройка !SEMTools упрощает задачу до применения паттернов RegEx на уровне слов как отдельных сущностей.
Найти слова по регулярному выражению
Процедура фактически разбивает ячейку на отдельные слова и проверяет каждое из них на соответствие вашему паттерну.
Какие это могут быть паттерны? Да самые разные: email-адреса, ИНН, даты. Можно искать профессиональную терминологию — медицинские термины на «-ит» (гастрит, бронхит), технические «ци(я|ю|и)» (оптимизация), должности (-ер, -ор, -ик).
Лингвистические паттерны позволяют находить слова на «-ние» (решение, внимание), прилагательные в превосходной степени (лучший, сильнейший), глаголы на «-овать» (использовать), слова с приставками (переделать, принести), аббревиатуры (ООО, IT, CRM) и специальные форматы типа №123/45 или N 67-89.
Извлечь слова по регулярному выражению
Вот так выглядит извлечение слов, содержащих латиницу и цифры, из массива слов, с помощью регулярного выражения:
([a-z]\d|\d[a-z])
Обратите внимание, что выражение означает, что цифра за буквой или буква за цифрой должны следовать непосредственно, без промежуточных символов между ними. Если нужно извлечь в том числе слова вида «asdf-13», «1234-d», понадобится обозначить возможность наличия символов между:
([a-z].*\d|\d.*[a-z]).
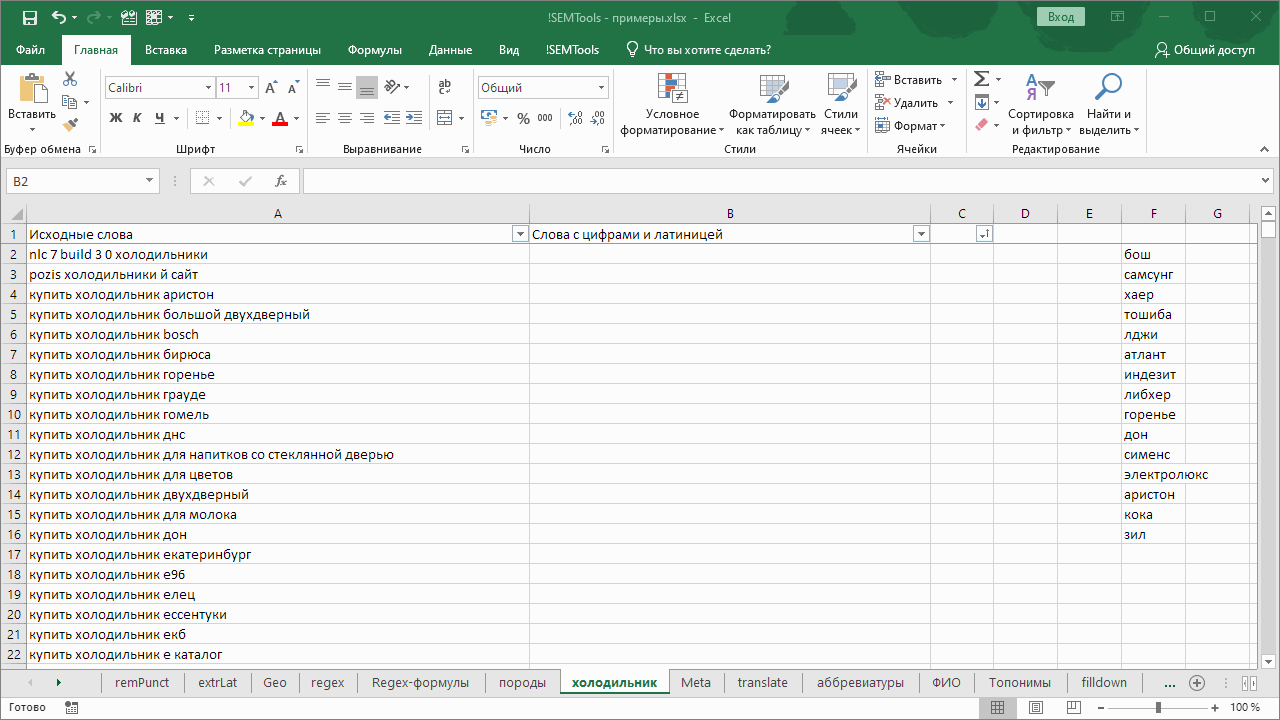
Удалить слова по регулярному выражению
Порой текст требует чистки от ненужных слов, и эти слова отличает соответствие определенному паттерну. Сформировав этот паттерн в виде регулярного выражения, можно легко удалить подобные слова из текста с помощью !SEMTools.
Очистить ячейки, не соответствующие регулярному выражению
Когда в вашем распоряжении массив данных, где могут быть ошибки, с которыми разбираться некогда, и при этом нужно извлечь только стопроцентно подходящие данные, можно воспользоваться регулярными выражениями для очистки нерелевантных.
Примеры:
- оставить ячейки с определенным количеством слов,
- оставить ячейки с определенным количеством символов,
- оставить ячейки, содержащие только цифры,
- оставить ячейки, содержащие только буквы,
- оставить ячейки, содержащие адрес электронной почты в доменной зоне .com и .ru.
Примеры использования «Извлечь ячейки по регулярному выражению».
Раскройте возможности Excel на максимум!
Используйте регулярные выражения в любой версии Excel с !SEMTools
Скажите пожалуйста, почему на regex101 эта регулярка работает (?<=\D[ ])(\d{0,3}[ ]?){0,3}\d+(,\d\d)
а у вас в надстройке выдает ошибку?
Не знаю, Антон, а в Google Spreadsheets работает?
А как с помощью регулярных выражений искать зеркальный номер? Например, 4915491 я хочу, чтобы находил из массива чисел?