Импорт данных из CSV, TSV и других текстовых форматов — повседневная задача для специалистов по SEO, аналитике и маркетингу. Выгрузки из рекламных кабинетов, поисковых систем, парсеров и CRM часто достигают сотен мегабайт, а иногда и гигабайт.
Стандартные методы Excel, которые отлично работают с небольшими файлами, дают сбой при серьёзных объёмах данных. В этой статье разберём, почему штатные инструменты не справляются и как правильно организовать импорт больших текстовых файлов.
Штатные методы импорта в Excel
Microsoft Excel предлагает несколько встроенных способов загрузки текстовых файлов. Рассмотрим их сильные и слабые стороны.
Самый очевидный способ — просто открыть CSV-файл как обычный документ Excel. При этом запускается Мастер импорта текстов, который позволяет выбрать разделитель и формат колонок.
Проблемы:
- Excel пытается загрузить весь файл целиком в оперативную память. Если файл превышает доступный объём RAM, программа зависает или выдает ошибку.
- На этапе открытия нет возможности отфильтровать ненужные строки — импортируются абсолютно все данные.
- При большом количестве колонок Excel может некорректно определить типы данных, превратив числовые идентификаторы в экспоненциальный формат.
2. Power Query (Получить и преобразовать)
Power Query (доступен в Excel 2016 и новее через вкладку «Данные» → «Получить данные» → «Из текстового файла») — гораздо более мощный инструмент. Он позволяет применять фильтры, менять типы данных и объединять файлы до загрузки в лист.
Казалось бы, идеальное решение? Но есть нюансы:
- Power Query также загружает весь файл в оперативную память в процессе обработки. Механизм построчного чтения отсутствует.
- При работе с файлами от 500 МБ и выше Power Query может «задуматься» на десятки минут, а индикатор прогресса не всегда позволяет понять, идёт процесс или программа зависла.
- Сложные преобразования и объединение нескольких больших файлов могут привести к исчерпанию памяти и вылету Excel.
Power Query — отличный инструмент для трансформации данных, но для простой фильтрации гигантских файлов он избыточен и неэффективен по памяти.
Почему могут неправильно отображаться данные
Отдельная боль при импорте — неправильное определение кодировки файла. Excel пытается открыть текстовый файл в кодировке, установленной в системе по умолчанию (обычно Windows-1251 для русскоязычной версии).
В результате:
- Файлы в UTF-8 без BOM открываются с кракозябрами вместо русского текста.
- Файлы в KOI8-R или других редких кодировках становятся полностью нечитаемыми.
- Приходится вручную пересохранять файл в нужной кодировке через Блокнот, что неудобно при регулярной работе.
Мастер импорта текстов позволяет выбрать кодировку на одном из шагов, но если корректная кодировка не определилась автоматически, найти в огромном списке корректную может быть проблематично.
Построчное чтение больших текстовых файлов
Главный недостаток всех штатных методов — попытка загрузить файл в память целиком. Для больших данных гораздо эффективнее подход построчного чтения (streaming).
В этом случае программа:
- Открывает файл и читает его по одной строке за раз.
- Сразу применяет условия фильтрации к текущей строке.
- Если строка подходит — записывает её в выходной файл или на лист Excel.
- Если нет — переходит к следующей строке, не храня её в памяти.
Таким образом, даже файл размером 100 ГБ (и больше!) может быть обработан на компьютере с 4 ГБ оперативной памяти. Единственное ограничение — скорость чтения с диска.
Именно этот подход реализован в двух инструментах надстройки !SEMTools, о которых пойдёт речь далее.
Далее: обзор двух методов выборки из больших CSV в !SEMTools — гибкого (с двумя условиями) и сверхбыстрого на базе ripgrep.
В !SEMTools есть два инструмента для выборки данных из CSV, которые решают эту проблему разными способами. Оба находятся в разделе «Web (парсинг, SEO, PPC)» → «Извлечь» → «Выборки из CSV».
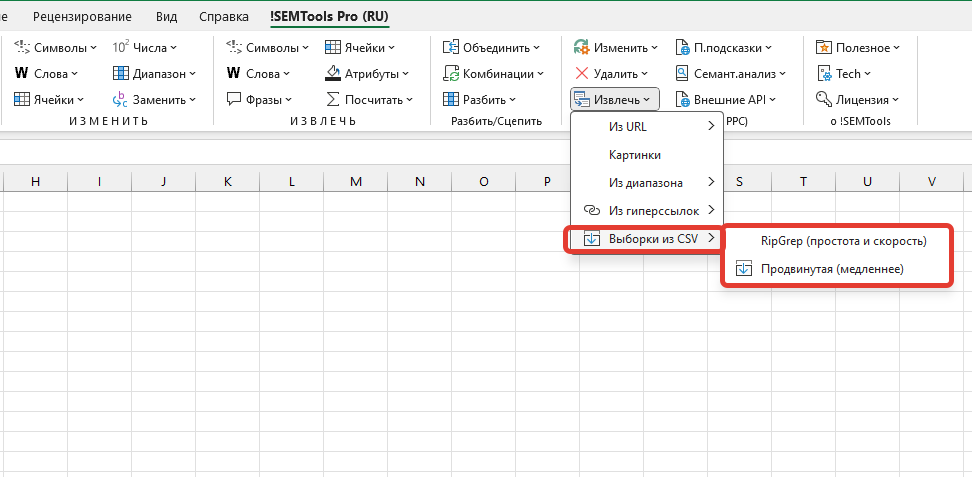
Метод 1: Гибкая выборка с условиями
Этот инструмент подойдёт, когда нужна тонкая настройка фильтрации. Вы можете задать два условия одновременно и комбинировать их логическими операторами «И» / «ИЛИ».
Возможности:
- 7 типов сравнения: содержит, начинается с, заканчивается на, удовлетворяет RegEx, больше чем, меньше чем, является вложенным для любого из (через запятую)
- Работа с двумя паттернами и выбор логического оператора
- Автоопределение разделителя при выборе файла и предпросмотр первых 10 строк
- Поддержка разных кодировок: UTF-8, Windows-1251, KOI8-R, KOI8-U, ISO-8859-5
- Выбор колонки для применения условий
Инструмент построчно читает исходный CSV, применяет условия и выводит подходящие строки на новый лист Excel. При достижении лимита строк (1 048 576) автоматически создаётся следующий лист.
Когда использовать: если нужны сложные условия, несколько паттернов, работа с регулярными выражениями.
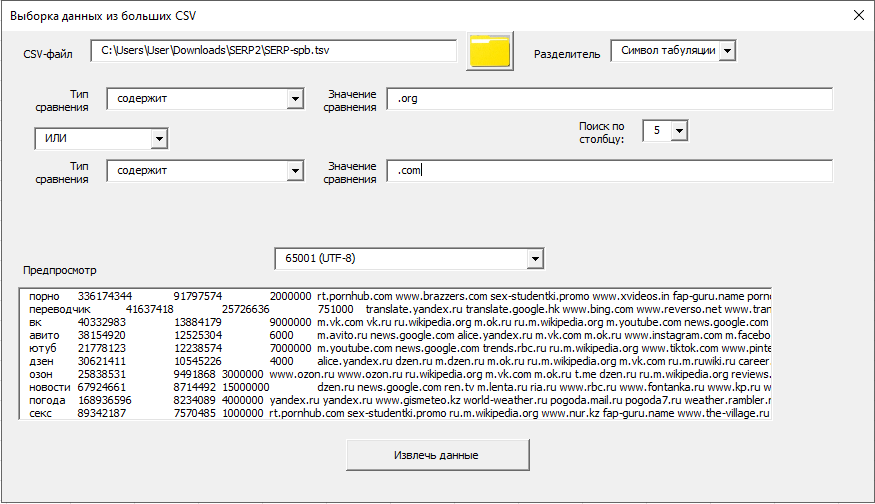
Метод 2: Быстрая фильтрация через ripgrep
Для максимальной скорости обработки очень больших файлов (от 500 МБ и выше) используется второй инструмент. Он основан на утилите ripgrep — одной из самых быстрых программ для построчного поиска.
Особенности:
- Максимальная производительность — ripgrep написан на Rust и использует все преимущества многопоточности
- Простота: выбираете TSV-файл, вводите паттерн, получаете отфильтрованный файл
- Работа с TSV (файлы с табуляцией как разделителем)
- Скрытый режим — командная строка не мешает работе
- Таймер выполнения — видите, сколько времени заняла фильтрация
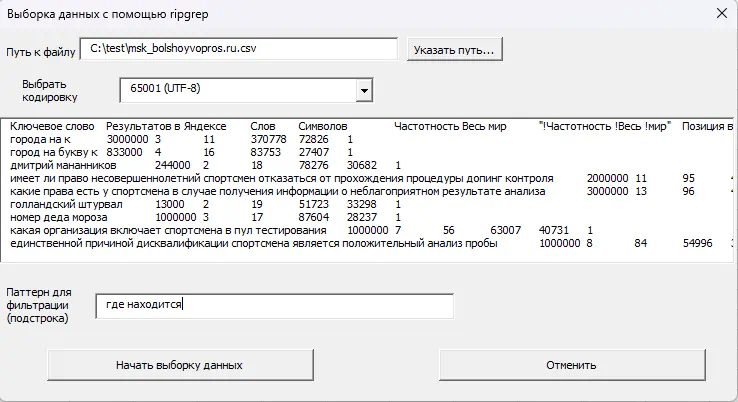
При первом запуске инструмент проверит наличие ripgrep в системе. Если утилита не найдена, появится предложение перейти на страницу с подробной инструкцией по установке.
Установка ripgrep
Для работы макроса фильтрации TSV-файлов необходима утилита ripgrep (rg.exe). Она должна находиться в папке C:\Windows\System32.
- Скачайте ripgrep с официальной github-страницы релизов:
https://github.com/BurntSushi/ripgrep/releases - Найдите раздел Assets последней версии.
- Скачайте архив для Windows (например, на момент написания этой статьи последняя версия для Windows —
ripgrep-15.1.0-x86_64-pc-windows-msvc.zip - Откройте архив (в windows можно просто зайти внутрь zip-папки).
- Найдите в папке файл rg.exe.
- Скопируйте rg.exe в папку
C:\Windows\System32\ - Готово — макрос сможет найти и использовать утилиту.
Проверка установки (не обязательно)
- Откройте командную строку (Win + R →
cmd→ Enter). - Выполните команду:
rg --version - Если вы видите информацию о версии — установка прошла успешно.
Когда использовать: если файл очень большой, а условие фильтрации простое (один паттерн, поиск по всем колонкам). Идеально для быстрого извлечения строк, содержащих определённое слово или фразу.
Сравнение методов
| Параметр | Гибкая выборка (VBA) | Быстрая фильтрация (ripgrep) |
|---|---|---|
| Скорость | Средняя, зависит от объёма | 🔴 Очень высокая |
| Сложность условий | 🔴 Высокая (2 паттерна, 7 типов, логические операторы) | Низкая (один паттерн) |
| Выбор колонки | 🔴 Да | Нет (поиск по всей строке) |
| Дополнительные требования | Нет | Требуется ripgrep (устанавливается один раз) |
| Вывод прямо на лист | Да | Нет (создаётся файл выборки) |
Инструменты дополняют друг друга и покрывают 99% сценариев работы с большими текстовыми файлами в Excel. К примеру, можно сделать базовую выборку с помощью ripgrep, а уже далее пользоваться сложными условиями выборки по результирующему файлу, который будет заметно меньше.