Как составить частотный словарь в Excel?
Для поисковой рекламы и SEO анализ n-грамм — один из самых эффективных методов. Однако долгое время n-gram анализ оставался в силу сложности реализации алгоритма доступен только крупным агентствам с программистами в штате, или продвинутым специалистам со знанием программирования.
Чтобы популяризовать подход и сделать его доступным всем, у кого есть Windows и Excel, инструменты для анализа n-грамм были реализованы в !SEMTools для Excel. Ниже перечислены различные подходы анализа со схематичными примерами.
Во всех кейсах создается отдельный лист с результатами подсчета, исходные данные никак не изменяются.
Простой анализ n-gram (анализ встречаемости)
Данный подход самый простой — берётся N-грамма и для неё анализируется её встречаемость в тексте.
Анализ частотности слов, или как посчитать в тексте уникальные слова и вывести списком с их встречаемостью
Как посчитать, сколько раз встречается слово в Excel-таблице? Если мы ищем лишь одно слово, может помочь формула СЧЁТЕСЛИ. Формула ниже посчитает количество строк, в которых встречается последовательность символов «слова» вне зависимости от их регистра.
=СЧЁТЕСЛИ(A1:A100;"*слова*")
Символ звездочки определяет, что перед и после указанной последовательности символов могут быть любые другие или их отсутствие. В связи с этим могут быть учтены строки со словами «словарь», «словарный» и т.д. Чтобы найти слова по точному совпадению, нужно добавить символ пробела в начало и конец всех ячеек столбца, и воспользоваться подсчетом с учетом пробелов:
=СЧЁТЕСЛИ(A1:A100;"* слова *")
Но и это решение не убережет нас от ситуаций, когда слово повторяется в строке 2 и более раз, если мы хотим посчитать все повторения. Т.к. формула считает именно строки.
Поэтому был реализован макрос в !SEMTools, с легкостью выполняющий эту задачу.
N-gram Анализ в Excel с !SEMTools
Для тех, кто предпочитает видеоинструкции, смотрите видео ниже:
Если же рассказать текстом, то читайте дальше :)
Частотный словарь (анализ встречаемости) слов
Выделяем текст (как правило, это множество ячеек Excel), выбираем в меню надстройки Семант. анализ — Составить частотный словарь — N-грамм — слов (1-gram).
Текст может быть как 5 строк, так и миллион строк — процедура максимально оптимизирована и даже на слабых компьютерах выполнение займет секунды или доли секунды. Главное, чтобы уникальных слов в тексте было не больше 1048575 — иначе их не получится вывести на лист. Но такая ситуация — редкость.
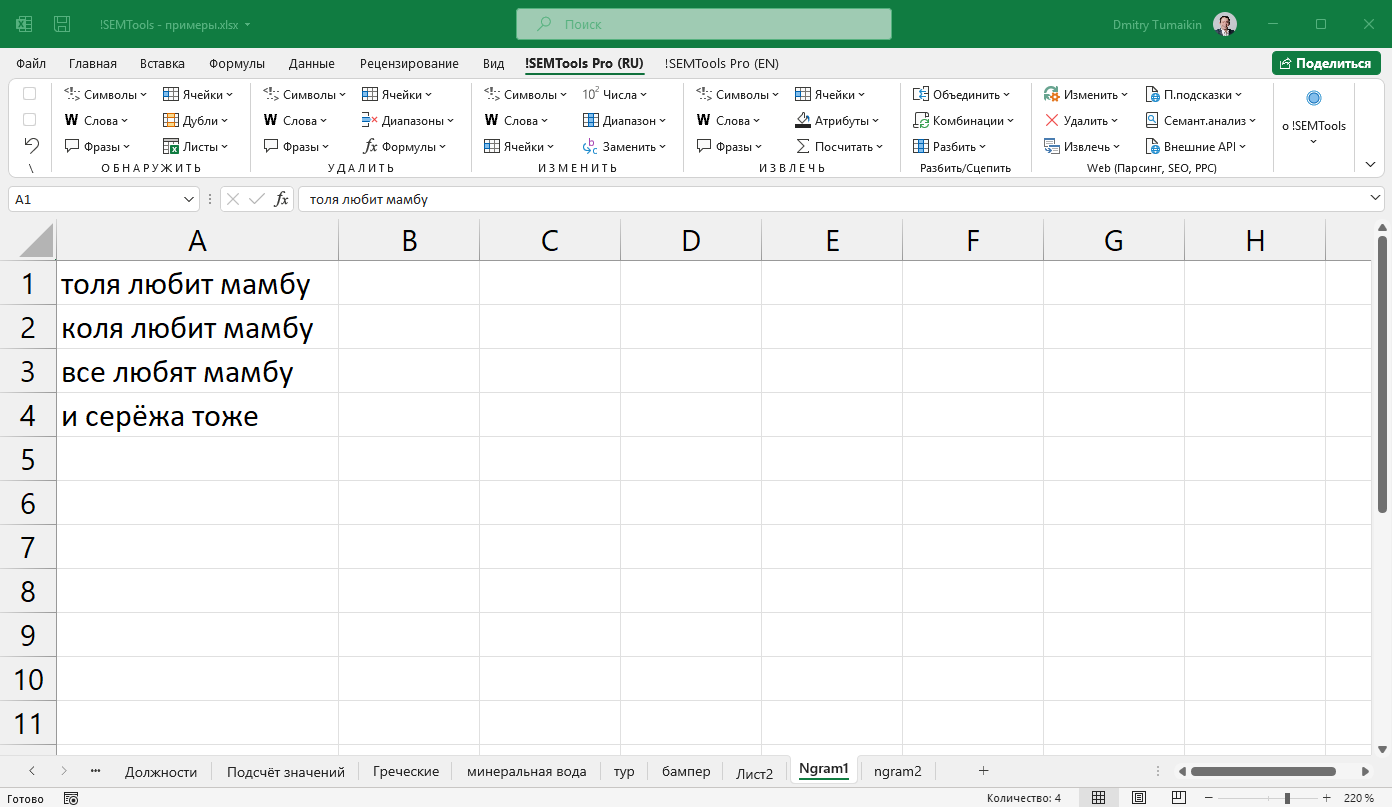
Можно обратить внимание, что разные словоформы рассматриваются как отдельные слова, поэтому, если нужно проанализировать встречаемость без учета словоформ, текст нужно предварительно лемматизировать. Тогда вы составите не просто частотный словарь слов, а частотный словарь лемм.
Анализ встречаемости биграмм (2-gram)
Аналогично предыдущему, но берутся биграммы — последовательности из двух слов. Как посчитать в данном случае триграммы и т.д., кажется, уже понятно.
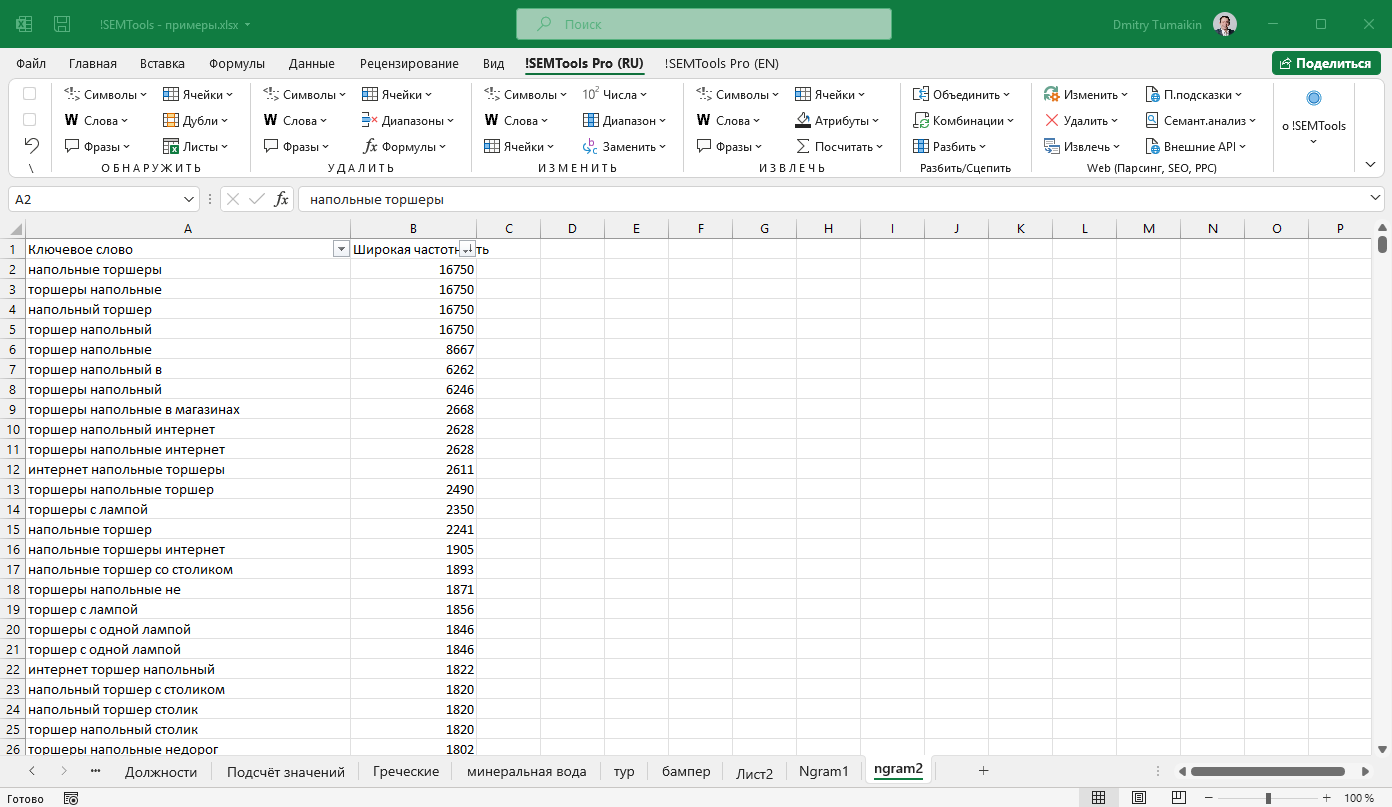
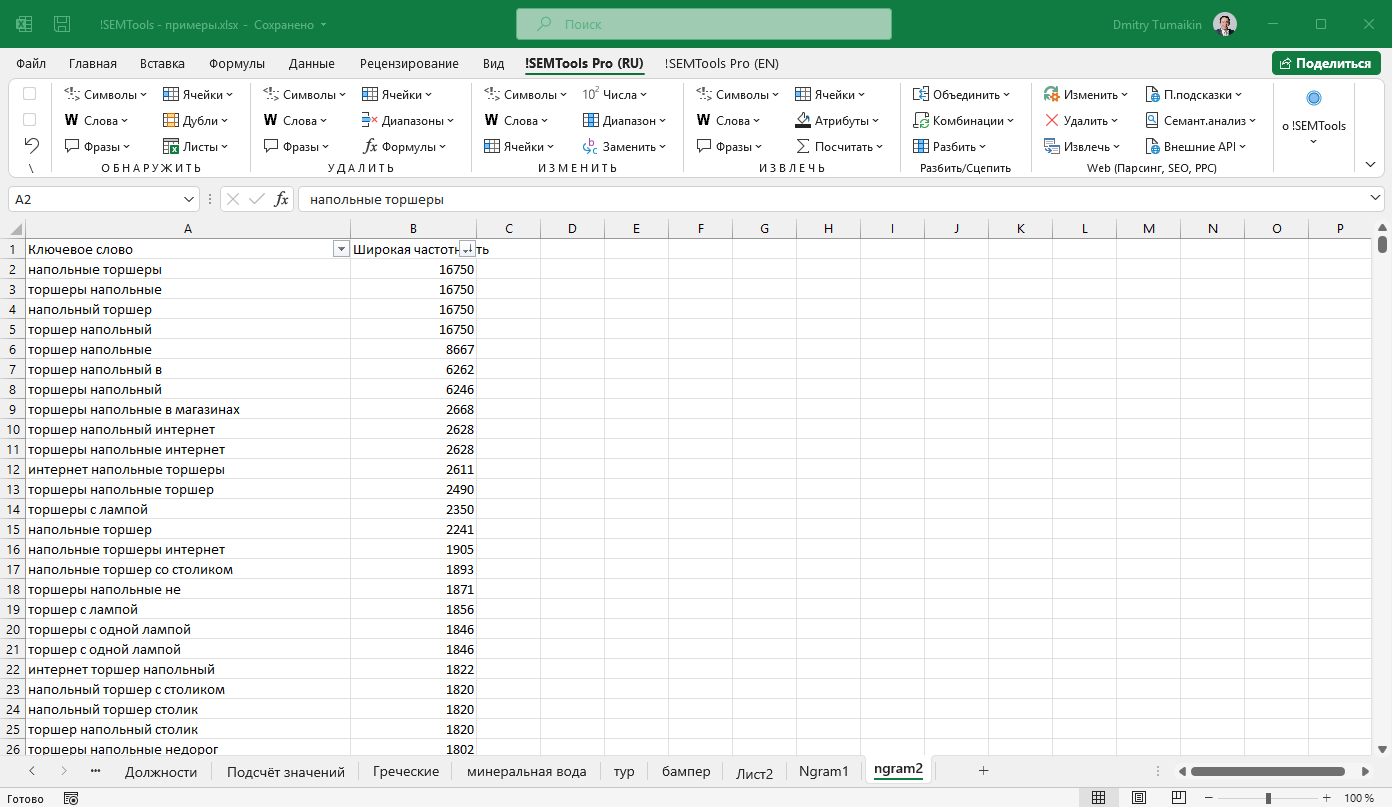
Анализ n-грамм с частотностью (или другой метрикой)
Когда текст состоит из фраз, и для каждой фразы известна определенная метрика (в поисковой рекламе это частотность), чтобы более достоверно измерить вес каждой словоформы или леммы, требуется производить анализ уже с учетом этой метрики.
В !SEMTools это вшито по умолчанию — просто нужно выделить два столбца вместе со столбцом используемой метрики. Аналогично можно составлять частотность биграмм, триграмм и т.д.
N-gram анализ по нескольким метрикам
Данный подход будет полезен PPC-специалистам для аналитики расчетных метрик, таких как CTR, CPC, CPA, CR, AOV, ROAS и тому подобные. Поскольку для их расчета используются несколько метрик, можно произвести n-gram анализ этих метрик и посчитать расчетные показатели в разрезе n-грамм.
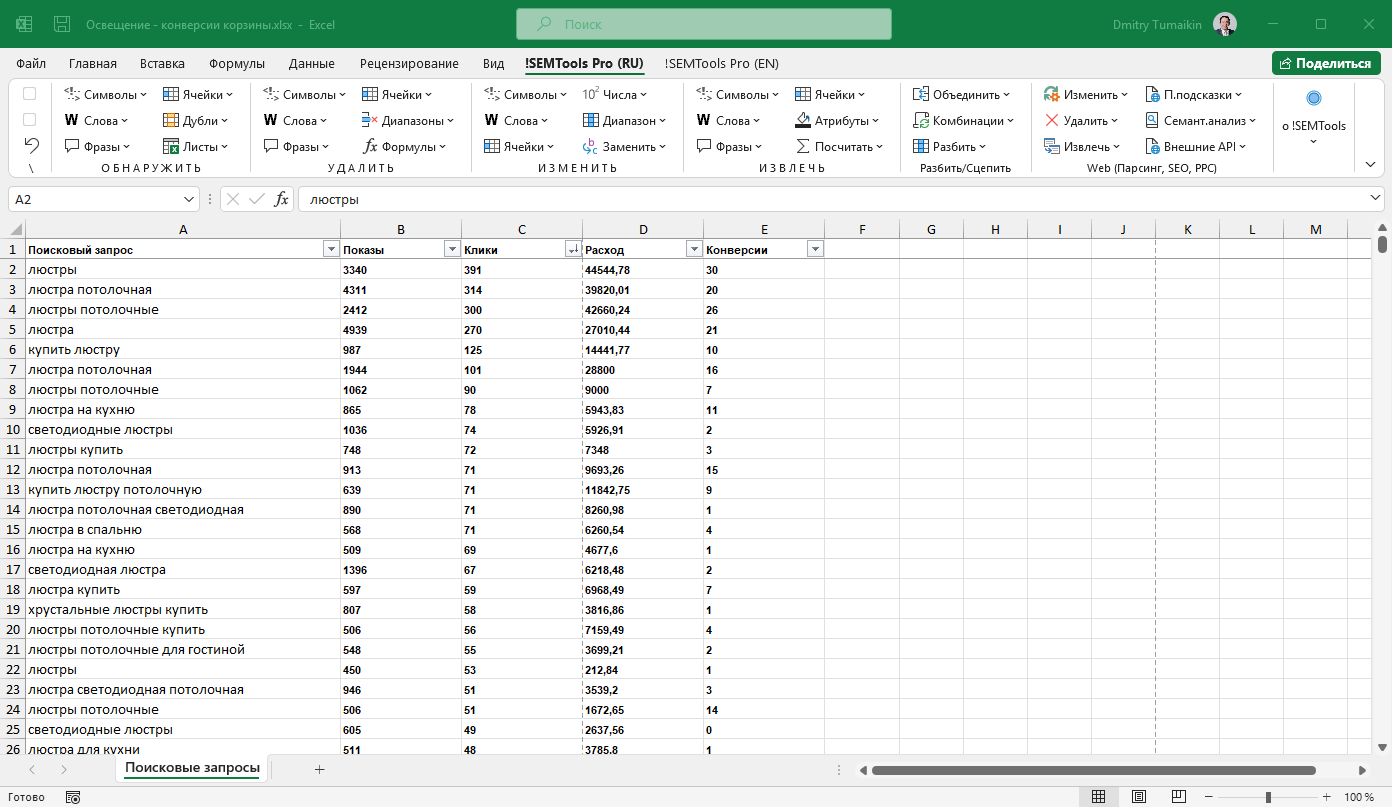
Анализ биграмм без учёта порядка слов
В примере выше заметно, что двусловные связки, обозначающие по сути одно и то же, присутствуют в разных строках, и у них у всех будут свои расчетные метрики эффективности.
Что, если бы была возможность не учитывать порядок слов в запросах и не учитывать словоформы? Именно эту возможность и даёт инструментарий ниже:
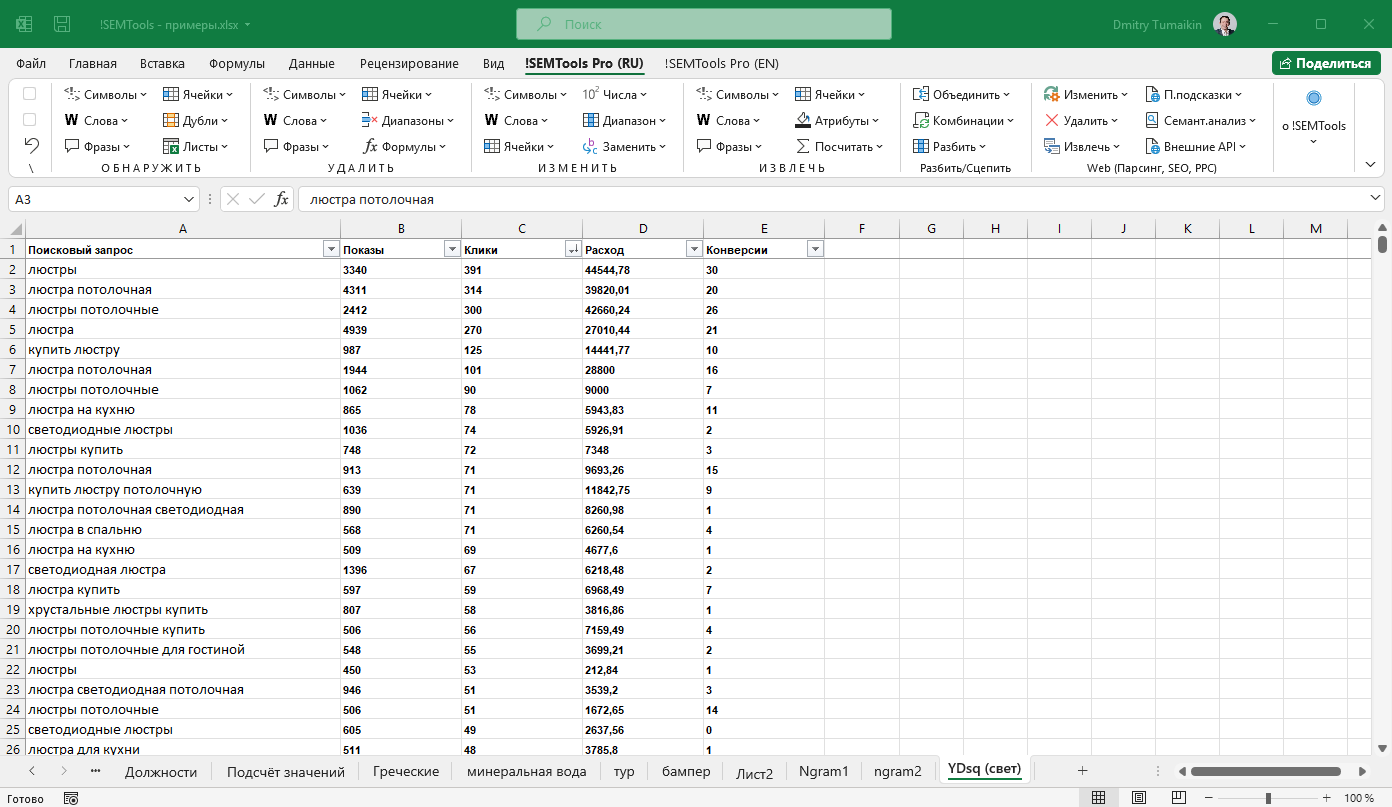
Чем полезен анализ биграмм без учёта порядка слов и словоформ
Такая аналитика может дать много полезных инсайтов. Выявить высококонверсионные связки слов для последующего интенсивного биддинга на них, например. Или, наоборот, выявления низкоконверсионных связок для исключения их из рекламы, в то время как слова, из которых они составлены, в среднем по больнице не выделялись низкой конверсией.
При этом связка в этом контексте — не пустой звук. Это именно Связка, т.е. взяты абсолютно все фразы, в которых эти два слова присутствуют (вообще где угодно во фразе), и не важно, в какой словоформе.
Почему это важно?
Дело в том, что слово в отрыве от другого слова может показывать себя средне, а с ним в паре демонстрирует высокую эффективность. Равно как и наоборот.
Заключение
Примеры, приведенные выше, позволяют производить анализ не только поисковых запросов или ключевых слов, но и любого текста, который будет дан на вход, вне зависимости от его длины. Нужно только удалить лишние пробелы, перевести весь текст в нижний регистр и можно производить анализ.
Если у вас остались вопросы — подписывайтесь на канал автора и задавайте вопросы в чате: https://t.me/semtoolschat
Часто сталкиваетесь с этой или похожими задачами при работе в Excel?
Скачивайте !SEMTools и начинайте экономить рабочее время, выделяя его для более важных задач!