Алгоритм подбора синонимов в Яндекс.Директе обсуждается в профессиональных сообществах практически ежедневно. К нему много вопросов. И основной — почему их нельзя отключить.
Все знают, что хотят убрать показы по синонимам в Яндекс.Директе, что это нужно делать, т.к. это повысит релевантность поисковых запросов и такую метрику, как «коэффициент проработки семантики«, о которой я уже писал ранее. Но непонятно, как это делать массово — строк с синонимами в отчете по поисковым запросам могут быть сотни, тысячи и десятки тысяч, и вручную работать с этим попросту нерентабельно.
Поэтому я решил сделать для профессионалов инструмент, который в один клик сможет обработать отчет по поисковым запросам и создать новые версии ключевых слов, с синонимами, добавленными в минус-слова на уровне ключевого слова.
Одним из самых основных, объемных и важных этапов нашей работы является чистка поисковых запросов — это постоянный источник для поиска и отбора новых ключей и минусов, от которого зависит если не успех всей рекламной кампании, то как минимум существенная ее часть.
Если в гугле вся работа с данным, иногда просто огромным, отчетом доведена практически до совершенства (хотя и там можно придумать себе всякие удобства, о чём дальше по тексту), то в директе приходится танцевать с бубном вокруг него, так как нет возможности исключить уже работающие в РК ключи, и это прямо боль боль боль.
И пока работники ЯДа соблаговолят решить нам эту простою задачу, решил поделиться с вами своими наработками, в том числе и по гуглу, вдруг это кому-то упростит жизнь и сэкономит рабочее время.
Будет интересно тем из вас, у кого есть маленькие дети, которым предстоит этому научиться. А так же тем из вас, кому интересны возможности Excel и Google Spreadsheets.
Многие знают меня как фаната Excel. Это недалеко от правды — я использовал его для самых разных нужд, рабочих и нет. Решил множество исследовательских задач. Попарсил немало сайтов, обработал гигабайты текстовых данных. Написал сотни макросов, создал свою надстройку для Excel и сделал ее платным продуктом, который даже оказался востребован, чему я очень рад. Но редко решал по-настоящему личные задачи, скорее решал общественные проблемы, задачи предприятий и клиентов.
Здесь же история про очень личное. Тем не менее, поскольку результат удивил меня самого, я решил поделиться им с вами.
Всем привет! Предполагаю, вы уже знаете, что такое минус-слова в контекстной рекламе и какова механика их работы. Надеюсь, готовые списки минус-слов помогут вам извлечь максимум пользы от рекламы в Яндекс.Директе или Google Ads. Но искренне рекомендую посмотреть мои рекомендации по сбору минус-слов в конце статьи, после самих списков.
Немного про стоп-слова
К сожалению, многие называют минус-слова стоп-словами и не видят разницы. Поэтому, если вы ищете типовой список стоп слов для контекстной рекламы, вы на самом деле ищете типовой список минус-слов, но пришли по адресу, т.к. у меня есть все :)
Плюсы и минусы списков минус-слов
Наверное, у каждого PPC-специалиста есть подобные списки. С одной стороны, это хорошо, т.к. превентивные меры могут сэкономить существенную часть бюджета. Тем не менее, у них есть и свои, незначительные, но минусы:
если в списке есть слова, которые не присутствуют в поисковом спросе в вашей тематике, добавлять их в аккаунт будет излишне и они не принесут пользы. Лишь вред от того, что займут место и не позволят в будущем вписаться в ограничения по минус-словам.
среди минус-слов могут оказаться «хорошие», по ним могли бы приходить платящие пользователи, но вы не догадались/сомневались и не дали им шанса.
Поэтому моя рекомендация — внимательно просматривайте списки минус-слов, прежде чем добавлять их в рекламу. Лучше всего не добавлять все слова (да и все их добавить точно не получится, лимитов не хватит), а воспользоваться функционалом надстройки !SEMTools извлечь слова или извлечь фразы совместно с этими списками на вашем семантическом ядре — так вы получите только те слова и фразы, которые имеют ненулевую частотность в вашей нише.
Списки минус-слов в !SEMTools
Поскольку списки могут пополняться новыми словами, и каждый раз проверять и скачивать их все неудобно, я добавил в свою надстройку как перечисленные в папке списки, так и процедуру их автоматического обновления. Все списки я периодически выкладываю на свой сервер, и процедура к нему стучится за обновлениями.
Как воспользоваться списками
Списки ниже представлены для ознакомления, но некоторые из них (для которых есть аналог в !SEMTools) недоступны для скачивания. Воспользоваться ими можно, установив надстройку !SEMTools (Pro). Просто выберите нужные вам маркеры и извлеките их в 1 клик:
Подробнее о том, как всё это выглядит и как ими пользоваться, рассказал на своем стриме:
Стандартный список минус-слов с общими терминами. Рекомендуется создавать как единый список на уровне аккаунта и применять ко всем кампаниям/группам объявлений в нем. Содержит слова, которые с высочайшей вероятностью не принесут продаж ни в какой тематике. При этом слова довольно популярны и встречаются почти всегда и везде. Вот он:
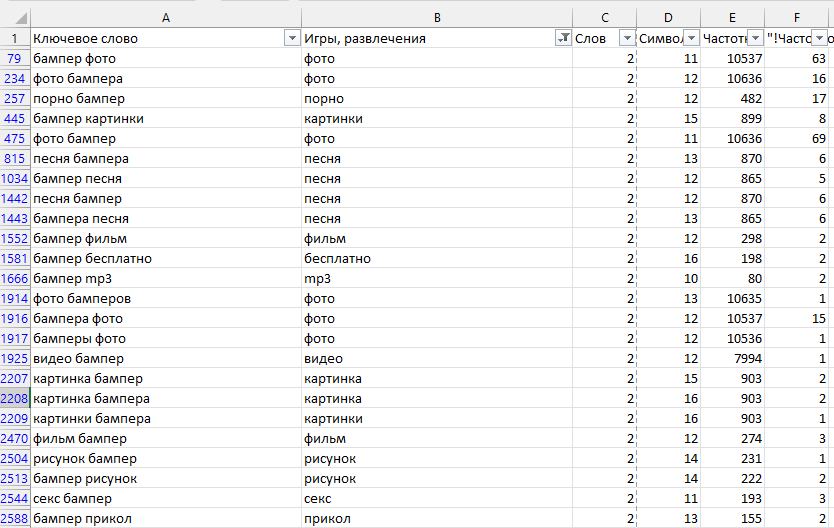
Гипотеза, из которой исходит автор, в том, что в этом списке только слова, связанные с развлечениями и другим контентом, который, как правило, в рунете ищут бесплатно. Однако воспринимайте даже это как гипотезу, т.к. развлечения — тоже индустрия, и она тоже неплохо монетизируется.
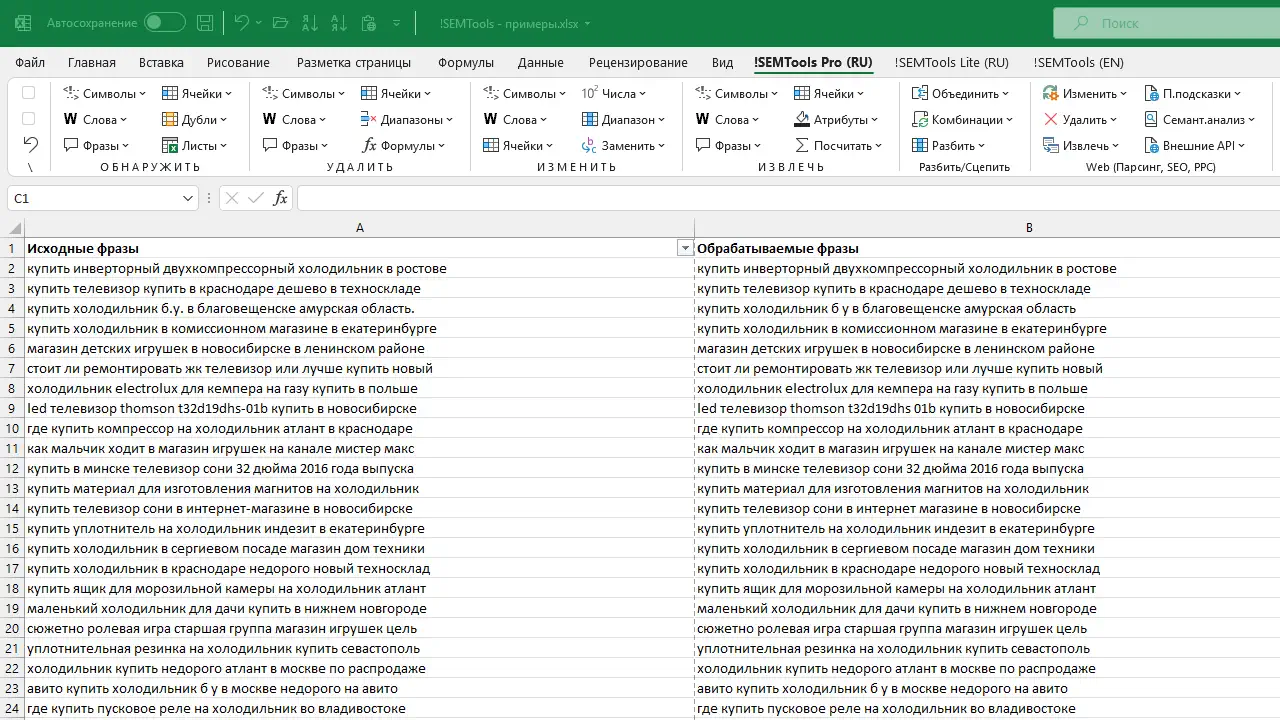
В надстройке !SEMTools список находится в меню Извлечь -> слова -> Целые слова -> Маркеры, вместе с множеством других.
Меню «извлечь маркеры игр и разлечений» в !SEMTools
А так будет выглядеть результат:
Минус-слова-города (топонимы)
С городами, как и с общим стандартным списком. Их нужно исключать внимательно, не без проверки. Некоторые названия продуктов, фабрик и прочие «хорошие» слова идентичны по написанию с некоторыми топонимами.
Города указаны вместе с некоторыми опечатками и упорядочены по убыванию частотности словоформы. При этом здесь не все возможные — в надстройке !SEMTools почти 40.000 уникальных словоформ названий городов и стран. Все попросту не выйдет добавить в аккаунт, поэтому взяты популярные.
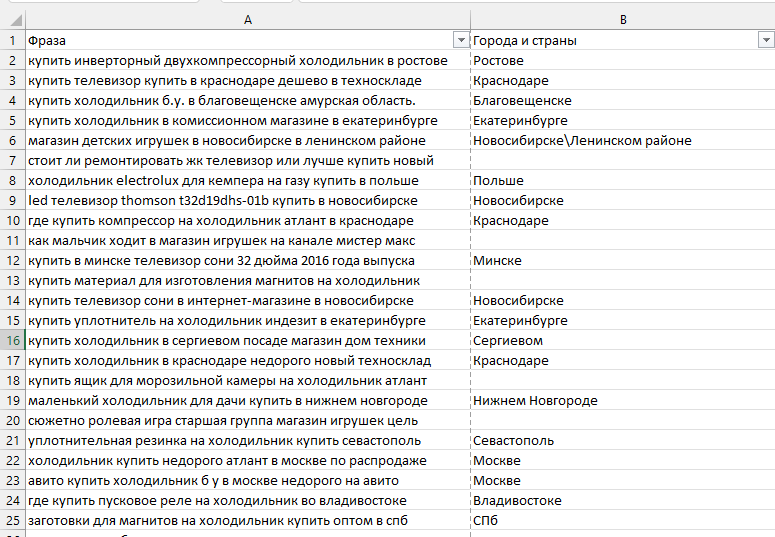
Функции извлечения топонимов из семантического ядра находятся в меню «ИЗВЛЕЧЬ» — «Извлечь фразы«. Из топонимов удалены омонимичные с нарицательными существительными. Например, в РФ есть населенный пункт Зима, но его в надстройке нет.
Поскольку над этим списком велась длительная и кропотливая работа, я не выкладываю его публично. Как извлекать топонимы с предлогами и без с помощью !SEMTools — смотрите тут.
Так выглядят извлеченные топонимы на коммерческой семантике:
Топонимы: список городов РФ
Города в списке указаны в именительном падеже, поэтому для более полной обработки вам может потребоваться процедура склонения фраз по падежам.
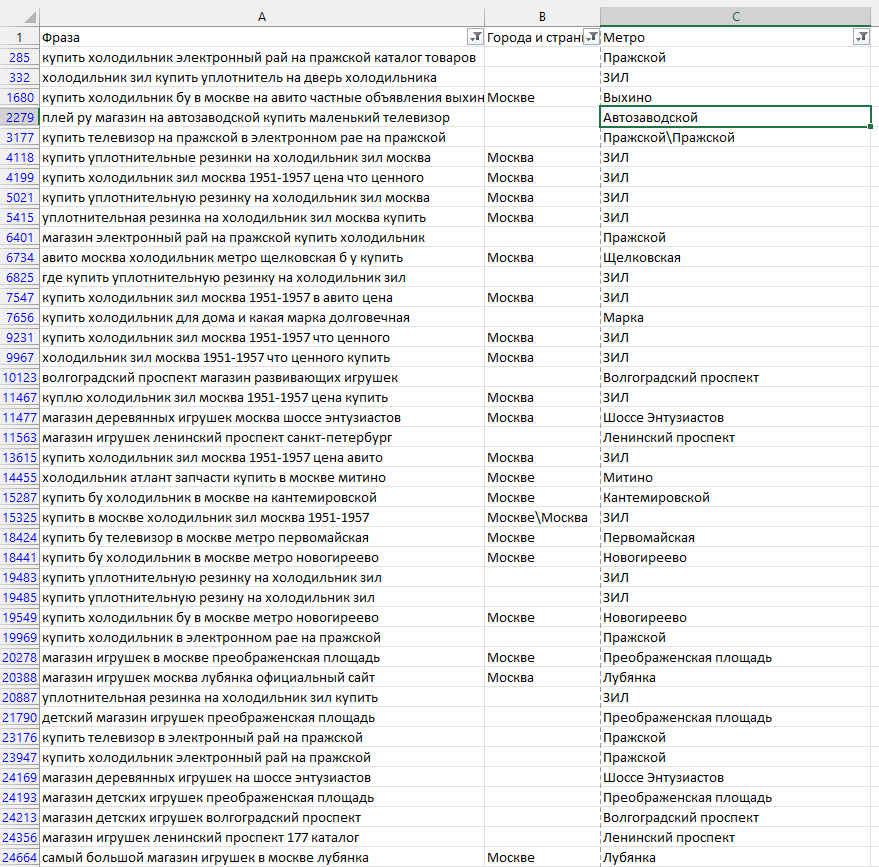
Так выглядит список извлечённых маркеров метро Москвы.
Обратите внимание, что убраны запросы, содержащие города кроме Москвы (поэтому желательно предварительно извлекать топонимы — города и страны).
Также убраны запросы, содержащие слова «обл», «область», т.к. Тульская, Калужская, Нижегородская и т.д. — это не только метро, но и области. И даже так, как видите, возможны неточности, связанные с омонимией. Беговая дорожка, холодильник ЗИЛ (есть в примере ниже).
Помимо нерелевантных регионов, бизнесу могут быть неинтересны пользователи, интересующиеся его товарами или услугами в информационных целях, или в аспекте другой тематики. Ситуаций, когда одни и те же слова используются с разным интентом, предостаточно. Все переплетено :)
Поэтому для каждой тематики стоит пробежаться по ключевым словам разными списками из представленных ниже. Текущие списки не финальны и постоянно обновляются. Также добавляются новые. Хотите помочь с наполнением или есть идеи? Заходите в telegram-чат надстройки !SEMTools!
Список будет полезен как тем, кто работает в автомобильной тематике (автозапчасти, автосервисы, продажа авто), так и тем, для кого она нерелевантна. Кириллическое написание и названия на латинице сопоставлены, что может быть очень удобно при запуске рекламных кампаний.
Нельзя назвать коммерческие маркеры минус-словами, однако для работы с рекламой они крайне важны и нужны. Это как глаголы и существительные с корнями «куп», «цен», «магазин», так и множество других слов и фраз, явно подразумевающих покупательский интент. Среди слов названия популярных интернет-магазинов и маркетплейсов, устойчивые словосочетания, используемые в коммерческих поисковых запросах.
Универсальные списки могут стать хорошим подспорьем на начальном этапе, но прорабатывать свою тематику детально нужно в любом случае. Ускорить процесс можно несколькими способами, о них далее.
Универсальный алгоритм подбора через стоп-слова
Считайте, что это бесплатный универсальный генератор минус-слов для любой ниши, связанной с продажей товаров или услуг. Позволяет собирать с высокой точностью сотни минус слов в считанные секунды. Он доступен бесплатно всем, установившим надстройку !SEMTools. Подробно об этом способе я рассказывал на SEMConf с докладом «Стоп-слова — друзья или враги?»
Извлечение глаголов
Практически любые глаголы, кроме «купить», «заказать», «стоит» и некоторых похожих, являются маркерами нерелевантного интента. Можно ли быстро извлечь глаголы из собранного семантического ядра на этапе проработки? Да, алгоритм довольно прост и он также реализован в надстройке.
У нерелевантных слов есть свойство «притягивать» друг друга. Поэтому, получив автоматически пул фраз, состоящий из нерелевантных интентов, и обработав его методом N-gram анализа, можно быстро собрать нерелевантных соседей.
Заключение
Прорабатывать минус-слова необходимо не только перед запуском, но и после запуска рекламы. Не полагайтесь на авось и анализируйте поисковые запросы. Вполне вероятно, что среди поисковых запросов будут выявлены новые нерелевантные слова и сочетания.
«Стоп-слова — служебные части речи и местоимения, а также любые слова, не несущие дополнительного смысла, которые автоматически исключаются из запроса пользователя при отборе объявлений для показа».
Справка Яндекс.Директа
Главное отличие стоп-слов в том, что они детерминированы, а минус-словом может быть любое слово.
В семантическом анализе текста понятие n-gram анализ — одно из ключевых. Такой анализ позволяет выявить все уникальные слова и словосочетания в тексте, а также подсчитать их встречаемость. Через анализ встречаемости n-грамм наиболее просто выявить т.н. ключевые слова — слова и фразы, встречающиеся в тексте заметно чаще остальных.
При работе с текстовыми данными часто приходится осуществлять такую операцию, как группировка фраз по определенным признакам. Моя любимая группировка — по маркерам. В надстройке я реализовал функции, которые позволяют совмещать умственное напряжение с автоматизацией рутины.